
(Windows11/10 WSL2版)
C言語は米合衆国のベル研究所でUNIXオペレーティングシステムのプログラムを書くために誕生した言語として知られています。その後、全世界にUNIX/Linuxが広がると共にC言語の利用者も多くなり、今日ではFORTRANやCOBOLのようによく利用されているプログラミング言語といえるのではないでしょうか。
また、C言語は記述の簡潔さにより、多くのプログラマーから支持されていますが、それだけではなくUNIX/Linux上のさまざまなツール群がこのC言語の流儀に習って設計されているものが多いため、C言語を直接使わない人でも一度C言語の文法を学習しておくことは大変有用なことではないでしょうか。 Windows11/10 WSL2版ではWindows11/10のコマンドプロンプトを起動させて、プログラムの作成、機械翻訳(コンパイル)、実行を行います。また、PowerShell上のC言語の処理系にはEmbarcadero Technologies社のC言語コンパイラー(bcc32c)をインストールして使用しました。
現在、Windows11/10上でLinux(Ubuntu)OSを動作させるWSL(Windwos Subsystem for Linux)という便利な仕組みが使えるようになっています。これによってUbuntu OS上の日本語カスタマイザーを使って、Windows11/10上の日本語C言語を動かすことができます。
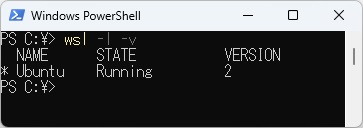
WSLのインストールについては、他のさまざまなサイトで紹介されていますので、そちらを参照してみてください。今回はWindwos11(バージョン23H2)上で、WSL2(Ubuntu22.04)をインストールして使っています。下図はPowerShellからWSLのバージョンを確認した様子です。(Window10もWSL2です)
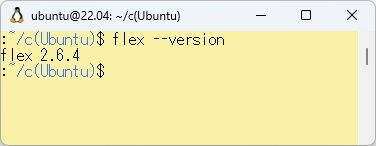
WSL2を起動させてインストールしたFLEXのバージョン(V 2.6.4)を確認してみます。
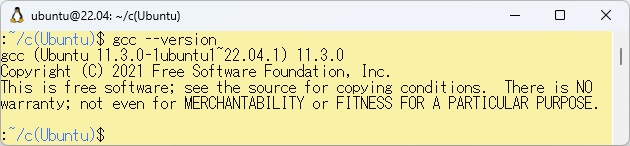
WSLやPowerShellで動作するC言語用の日本語カスタマイザーは、FLEXのプログラムを使います。それをC言語処理系によって翻訳することにより、プログラムを実行することができます。従って日本語カスタマイザーを動かすにはWSL上でFLEXとC言語の処理系(gcc)が必要となります。以下に今回使用したWSL2上のgccバージョンを示します。
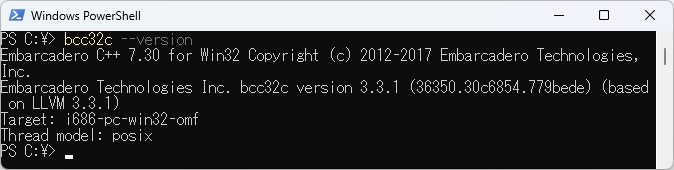
また、PowerShellで動作するclang準拠のC言語処理系、bcc32cのバージョン(フリー入手可能 V7.30)を以下に示します。
WSL上で日本語で書かれたC言語ファイルの名前を仮にファイル1.jcとすると
>jcc ファイル1
というバッチコマンドによりファイル1.cを生成し、さらに翻訳(コンパイル)、結合(リンク)して、実行可能形式ファイルであるファイル1を生成します。 PowerShell上のbcc32cで動作させるために、ファイル1.cのみ生成するには、「-c」オプションを付けるようにしています。 このとき、jcpp_rulew(C++と共用)がC言語用の日本語カスタマイザー1パス目の実行で、jcpp_rulew2は2パス目の実行を行っています。 このとき、WSL用の日本語カスタマイザー「jcpp_rulew」では、読み込むテキストファイルの改行処理に、UbuntuのLF(\n)に加え、WindowsのCRLF(\r\n)でも認識できるようにしてあります。
Windows11のエクスプローラーからUbuntuフォルダにアクセスする場合には、ペンギンマークのLinuxのところをクリックします。

実際のC言語プログラムでの応用例
Windows 7版はこちら(注:OSサポート期限切れ)
Windows XP版はこちら(注:OSサポート期限切れ)
以下に応用例について説明します。これは硝酸銀の水溶液に電流(電源や電池のマイナス側からプラス側へ移動する、実際のエネルギーとしての電子の流れという意味)を流して、電気分解したときに析出する銀の質量を求めるためのものです。
/* 硝酸銀に1~10アンペアの電流を1時間流して電気分解したとき、陰極に出てくる銀の質量を求める */
#include <stdio.h>
#日本語定義 整数型 "int"
#日本語定義 実数型 "float"
#日本語定義 型なし "void"
#日本語定義 印字 "printf"
#日本語定義 はじまり "main"
#日本語定義 繰り返し "while"
#日本語定義 通常終了 "return 0"
#日本語定義 電流を流したときの電気量
#日本語定義 電流値
#日本語定義 1時間の秒数
#日本語定義 電子がもつ基準の電気量
#日本語定義 銀の原子量
#日本語定義 出てくる銀の質量
#日本語定義 上限
#日本語定義 下限
#日本語定義 きざみ幅
整数型 はじまり(型なし)
{
整数型 電流値,上限,下限,きざみ幅;
実数型 1時間の秒数 = 3600.0,
電子がもつ基準の電気量 = 96500.0,
電流を流したときの電気量,
銀の原子量 = 107.9,
出てくる銀の質量;
上限 = 10;
下限 = 1;
きざみ幅 = 1;
電流値 = 下限;
繰り返し ( 電流値 <= 上限 ) {
電流を流したときの電気量 = (実数型)電流値 *1時間の秒数 / 電子がもつ基準の電気量;
出てくる銀の質量 = 銀の原子量 * 電流を流したときの電気量;
印字( "電流値が%dアンペアののとき、出てくる銀の質量は%6.3fgです。\n", 電流値, 出てくる銀の質量 );
電流値 = 電流値 + きざみ幅;
}
通常終了;
}
例題W-1
これは次のようなC言語のコードに展開されます。(以降リスト中の余分な空白行は適当に削除して掲載しています)
/* 硝酸銀に1~10アンペアの電流を1時間流して電気分解したとき、陰極に出てくる銀の質量を求める */
#include <stdio.h>
int main(void)
{
int jp_str_1,jp_str_6,jp_str_7,jp_str_8;
float jp_str_2 = 3600.0,
jp_str_3 = 96500.0,
jp_str_0,
jp_str_4 = 107.9,
jp_str_5;
jp_str_6 = 10;
jp_str_7 = 1;
jp_str_8 = 1;
jp_str_1 = jp_str_7;
while ( jp_str_1 <= jp_str_6 ) {
jp_str_0 = (float)jp_str_1 *jp_str_2 / jp_str_3;
jp_str_5 = jp_str_4 * jp_str_0;
printf( "電流値が%dアンペアののとき、出てくる銀の質量は%6.3fgです。\n", jp_str_1, jp_str_5 );
jp_str_1 = jp_str_1 + jp_str_8;
}
return 0;
}
例題W-1を展開したもの
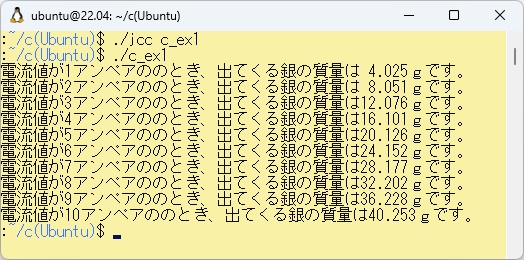
例題W-1の展開されたC言語プログラムをWSL上でコンパイルして実行させた結果は以下のとおりです。
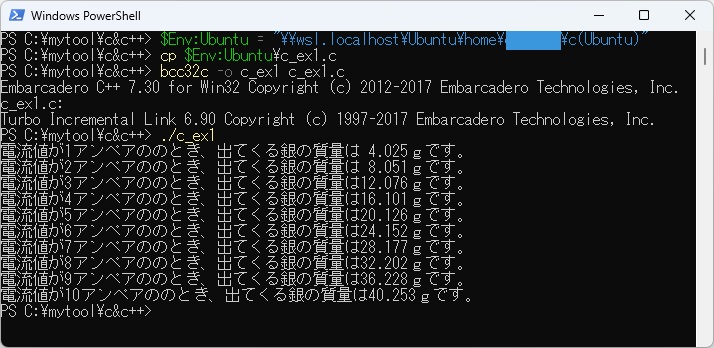
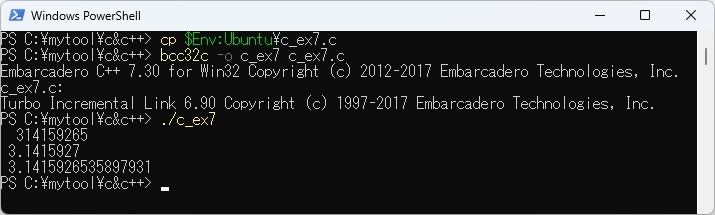
また、WSL上にあるc_ex1.cをPowerSheshell上にコピーするときに、以下のように環境変数$Env:ubuntuを使ってパスを指定し、 PowerShellのcpコマンドでコピーすることもできます。 PowerShell上のbcc32cでc_ex1.cをコンパイルして実行させた結果は以下のとおりです。
次に例題W-1の計算式の部分を関数化したものを例題W-2とします。
/* 硝酸銀に1~10アンペアの電流を1時間流して電気分解したとき、陰極に出てくる銀の質量を求める */
#include <stdio.h>
#日本語定義 整数型 "int"
#日本語定義 実数型 "float"
#日本語定義 型なし "void"
#日本語定義 印字 "printf"
#日本語定義 はじまり "main"
#日本語定義 繰り返し "while"
#日本語定義 通常終了 "return 1"
#日本語定義 戻る "return"
#日本語定義 電流を流したときの電気量
#日本語定義 電流値
#日本語定義 1時間の秒数
#日本語定義 電子がもつ基準の電気量
#日本語定義 銀の原子量
#日本語定義 電気量を求める
#日本語定義 上限
#日本語定義 下限
#日本語定義 きざみ幅
整数型 はじまり(型なし)
{
整数型 電流値,上限,下限,きざみ幅;
実数型 電気量を求める( 整数型 );
上限 = 10;
下限 = 1;
きざみ幅 = 1;
電流値 = 下限;
繰り返し ( 電流値 <= 上限 ) {
印字( "電流値が%dアンペアののとき、出てくる銀の質量は%6.3fgです。\n", 電流値, 電気量を求める(電流値) );
電流値 = 電流値 + きざみ幅;
}
戻る(0);
}
実数型 電気量を求める( 電流値 )
整数型 電流値;
{
実数型 1時間の秒数 = 3600.0,
電子がもつ基準の電気量 = 96500.0,
電流を流したときの電気量,
銀の原子量 = 107.9;
電流を流したときの電気量 = (実数型)電流値 *1時間の秒数 / 電子がもつ基準の電気量;
戻る( 銀の原子量 * 電流を流したときの電気量 );
}
例題W-2
これは次のようなC言語のコードに展開されます。
/* 硝酸銀に1~10アンペアの電流を1時間流して電気分解したとき、陰極に出てくる銀の質量を求める */
#include <stdio.h>
int main(void)
{
int jp_str_1,jp_str_6,jp_str_7,jp_str_8;
float jp_str_5( int );
jp_str_6 = 10;
jp_str_7 = 1;
jp_str_8 = 1;
jp_str_1 = jp_str_7;
while ( jp_str_1 <= jp_str_6 ) {
printf( "電流値が%dアンペアののとき、出てくる銀の質量は%6.3fgです。\n", jp_str_1, jp_str_5(jp_str_1) );
jp_str_1 = jp_str_1 + jp_str_8;
}
return(0);
}
float jp_str_5( jp_str_1 )
int jp_str_1;
{
float jp_str_2 = 3600.0,
jp_str_3 = 96500.0,
jp_str_0,
jp_str_4 = 107.9;
jp_str_0 = (float)jp_str_1 *jp_str_2 / jp_str_3;
return( jp_str_4 * jp_str_0 );
}
例題W-2を展開したもの
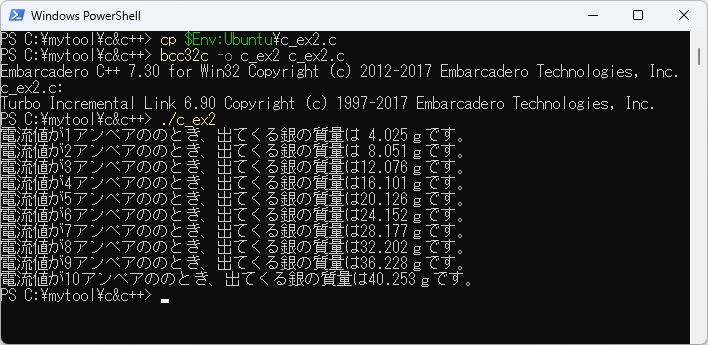
例題W-2の展開されたC言語プログラムをWSL上でコンパイルして実行させた結果は以下のとおりです。
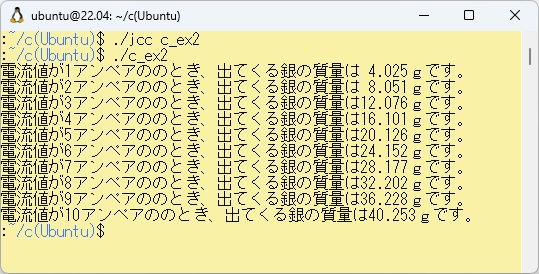
また、PowerShell上のbcc32cでc_ex2.cをコンパイルして実行させた結果は以下のとおりです。
次に構造体に関するプログラムを例題W-3とします。
/* 個人情報を印字する */
#include <stdio.h>
#日本語定義 構造体 "struct"
#日本語定義 整数型 "int"
#日本語定義 文字型 "char"
#日本語定義 型なし "void"
#日本語定義 印字 "printf"
#日本語定義 はじまり "main"
#日本語定義 正常終了 "return 0"
#日本語定義 個人情報型 "person"
#日本語定義 名前
#日本語定義 年齢
#日本語定義 性別
#日本語定義 生まれた年
#日本語定義 生まれた月
#日本語定義 生まれた日
構造体 個人情報型 {
文字型 名前[30];
整数型 年齢;
文字型 性別[4];
整数型 生まれた年;
整数型 生まれた月;
整数型 生まれた日;
};
#日本語定義 鈴木さんの記録
#日本語定義 山田さんの記録
整数型 はじまり(型なし)
{
構造体 個人情報型 鈴木さんの記録 = {"鈴木太郎",46,"男",1963,2,14};
構造体 個人情報型 山田さんの記録 = {"山田花子",35,"男",1974,8,23};
印字("名前=%s\n",鈴木さんの記録.名前);
印字("年齢=%d歳\n",鈴木さんの記録.年齢);
印字("性別=%s\n",鈴木さんの記録.性別);
印字("生年月日=%d年",鈴木さんの記録.生まれた年);
印字("%d月",鈴木さんの記録.生まれた月);
印字("%d日生まれ\n\n",鈴木さんの記録.生まれた日);
印字("名前=%s\n",山田さんの記録.名前);
印字("年齢=%d歳\n",山田さんの記録.年齢);
印字("性別=%s\n",山田さんの記録.性別);
印字("生年月日=%d年",山田さんの記録.生まれた年);
印字("%d月",山田さんの記録.生まれた月);
印字("%d日生まれ\n",山田さんの記録.生まれた日);
正常終了;
}
例題W-3
やはり日本語が多用されているプログラムは大変読みやすいと思います。これは次のようなC言語のコードに展開されます。
/* 個人情報を印字する */
#include <stdio.h>
struct person {
char jp_str_0[30];
int jp_str_1;
char jp_str_2[4];
int jp_str_3;
int jp_str_4;
int jp_str_5;
};
int main(void)
{
struct person jp_str_6 = {"鈴木太郎",46,"男",1963,2,14};
struct person jp_str_7 = {"山田花子",35,"男",1974,8,23};
printf("名前=%s\n",jp_str_6.jp_str_0);
printf("年齢=%d歳\n",jp_str_6.jp_str_1);
printf("性別=%s\n",jp_str_6.jp_str_2);
printf("生年月日=%d年",jp_str_6.jp_str_3);
printf("%d月",jp_str_6.jp_str_4);
printf("%d日生まれ\n\n",jp_str_6.jp_str_5);
printf("名前=%s\n",jp_str_7.jp_str_0);
printf("年齢=%d歳\n",jp_str_7.jp_str_1);
printf("性別=%s\n",jp_str_7.jp_str_2);
printf("生年月日=%d年",jp_str_7.jp_str_3);
printf("%d月",jp_str_7.jp_str_4);
printf("%d日生まれ\n",jp_str_7.jp_str_5);
return 0;
}
例題W-3を展開したもの
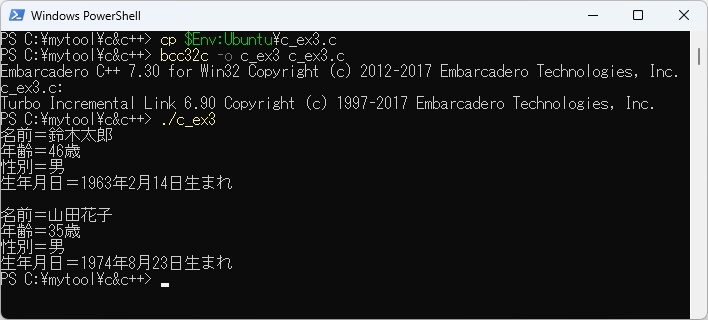
ここで、日本語定義の部分についてですが、定義はプログラム中のどこに現われても構いませんが、同じ定義を二度以上使うことはできません。(この場合にはFLEXが警告を通知します) 例題W-3の展開されたC言語プログラムを実行させた結果は以下のとおりです。
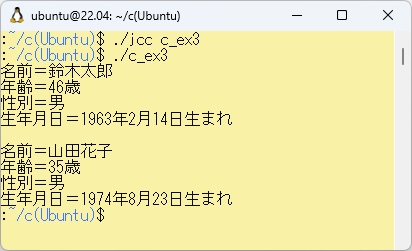
また、PowerShell上のbcc32cでc_ex3.cをコンパイルして実行させた結果は以下のとおりです。
さらにポインタと配列を扱うプログラムを例題W-4とします。
/* 引数をそのまま書き出す */
#include <stdio.h>
#日本語定義 整数型 "int"
#日本語定義 文字への番地型| "char *"
#日本語定義 印字 "printf"
#日本語定義 反復 "for"
#日本語定義 はじまり "main"
#日本語定義 もし "if"
#日本語定義 それ以外 "else"
#日本語定義 中味| "*"
#日本語定義 初期化なし " "
#日本語定義 の場合は、 " "
#日本語定義 を実行する " "
#日本語定義 正常終了 "return 0 "
#日本語定義 引数の数 "argc"
#日本語定義 引数配列 "argv"
整数型 はじまり(引数の数,引数配列)
整数型 引数の数;
文字への番地型|引数配列[];
{
反復 ( 初期化なし; 引数の数 > 1; --引数の数 ) {
印字( "%s", 中味|++引数配列 );
もし( 引数の数 <= 2 )の場合は、印字("\n")を実行する;
それ以外の場合は、 印字(" " )を実行する;
}
正常終了;
}
例題W-4
C言語の規約により、mainの関数に渡されるパラメータは、引数の数と文字列としての引数配列があります。 引数がない場合には引数の数は1となり、そのときの引数配列は[0]要素に実行プログラム名が格納されますが、 引数が1つ以上ある場合には、引数の数は2以上で、引数の文字列は引数配列の[1]要素から順番に格納されます。
/* 引数をそのまま書き出す */
#include <stdio.h>
int main(argc,argv)
int argc;
char *argv[];
{
for ( ; argc > 1; --argc ) {
printf( "%s", *++argv );
if( argc <= 2 ) printf("\n") ;
else printf(" " ) ;
}
return 0 ;
}
例題W-4を展開したもの
WSL上で例題W-4の展開されたC言語プログラムを実行させた結果は以下のとおりです。
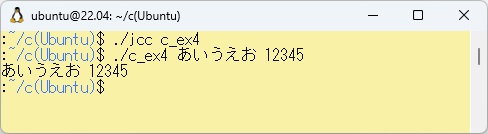
また、PowerShell上のbcc32cでc_ex4.cをコンパイルして実行させた結果は以下に示します。
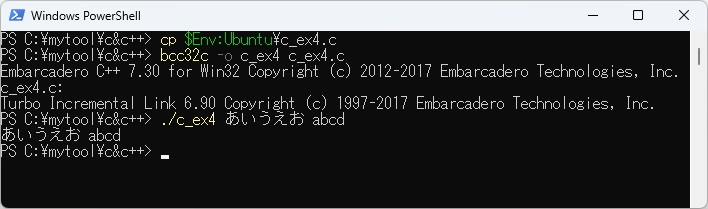
WSL上のC言語処理系gccで取り扱える各データ型のサイズを求める日本語プログラムを以下に示します。
/*
各型のサイズを求める
*/
#include <stdio.h>
#include <immintrin.h>
#日本語定義 文字型 "char"
#日本語定義 符号なし文字型 "unsigned char"
#日本語定義 整数型 "int"
#日本語定義 付号なし整数型 "unsigned int"
#日本語定義 半整数型 "short int"
#日本語定義 長い整数型 "long int"
#日本語定義 実数型 "float"
#日本語定義 倍精度型 "double"
#日本語定義 長い倍精度型 "long double"
#日本語定義 整数ベクトル計算型 "__m128i"
#日本語定義 実数ベクトル計算型 "__m128"
#日本語定義 はじまり "main"
#日本語定義 サイズを調べる "sizeof"
#日本語定義 印字 "printf"
#日本語定義 正常終了 "return 0"
整数型 はじまり() {
印字("文字型(char)のサイズ= %ld byte\n",サイズを調べる(文字型));
印字("符号なし文字型(unsigned char)のサイズ= %ld byte\n",サイズを調べる(符号なし文字型));
印字("整数型(int)のサイズ= %ld byte\n",サイズを調べる(整数型));
印字("付号なし整数型(unsigned int)のサイズ= %ld byte\n",サイズを調べる(付号なし整数型));
印字("半整数型(short int)のサイズ= %ld byte\n",サイズを調べる(半整数型));
印字("長い整数型(long int)のサイズ= %ld byte\n",サイズを調べる(長い整数型));
印字("実数型(float)のサイズ= %ld byte\n",サイズを調べる(実数型));
印字("倍精度型(double)のサイズ= %ld byte\n",サイズを調べる(倍精度型));
印字("長い倍精度型(long double)のサイズ= %ld byte\n",サイズを調べる(長い倍精度型));
印字("整数ベクトル計算型(__m128i)のサイズ= %ld byte\n",サイズを調べる(整数ベクトル計算型));
印字("実数ベクトル計算型(__m128)のサイズ= %ld byte\n",サイズを調べる(実数ベクトル計算型));
正常終了;
}
例題W-5 WSL上のgccで動作するc_ex5w.jc
/*
各型のサイズを求める
*/
#include <stdio.h>
#include <immintrin.h> // SSE命令セットのヘッダー
int main() {
printf("文字型(char)のサイズ= %ld byte\n",sizeof(char));
printf("符号なし文字型(unsigned char)のサイズ= %ld byte\n",sizeof(unsigned char));
printf("整数型(int)のサイズ= %ld byte\n",sizeof(int));
printf("付号なし整数型(unsigned int)のサイズ= %ld byte\n",sizeof(unsigned int));
printf("半整数型(short int)のサイズ= %ld byte\n",sizeof(short int));
printf("長い整数型(long int)のサイズ= %ld byte\n",sizeof(long int));
printf("実数型(float)のサイズ= %ld byte\n",sizeof(float));
printf("倍精度型(double)のサイズ= %ld byte\n",sizeof(double));
printf("長い倍精度型(long double)のサイズ= %ld byte\n",sizeof(long double));
printf("整数ベクトル計算型(__m128i)のサイズ= %ld byte\n",sizeof(__m128i));
printf("実数ベクトル計算型(__m128)のサイズ= %ld byte\n",sizeof(__m128));
return 0;
}
例題W-5 WSL上のc_ex5w.jcの展開したもの
このプログラムをコンパイルして実行させた結果を以下に示します。
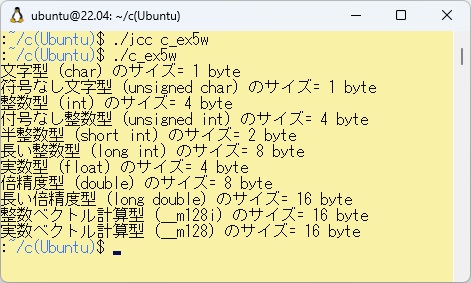
PowerShell上のC言語処理系bcc32cで取り扱える各データ型のサイズを求める日本語プログラムを以下に示します。
/*
各型のサイズを求める
*/
#include <stdio.h>
#define __SSE2__
#define __SSE__
#define __MMX__
#include <emmintrin.h>
#日本語定義 文字型 "char"
#日本語定義 符号なし文字型 "unsigned char"
#日本語定義 整数型 "int"
#日本語定義 付号なし整数型 "unsigned int"
#日本語定義 半整数型 "short int"
#日本語定義 長い整数型 "long int"
#日本語定義 実数型 "float"
#日本語定義 倍精度型 "double"
#日本語定義 長い倍精度型 "long double"
#日本語定義 整数ベクトル計算型 "__m128i"
#日本語定義 実数ベクトル計算型 "__m128"
#日本語定義 はじまり "main"
#日本語定義 サイズを調べる "sizeof"
#日本語定義 印字 "printf"
#日本語定義 正常終了 "return 0"
整数型 はじまり() {
印字("文字型(char)のサイズ= %d byte\n",サイズを調べる(文字型));
印字("符号なし文字型(unsigned char)のサイズ= %d byte\n",サイズを調べる(符号なし文字型));
印字("整数型(int)のサイズ= %d byte\n",サイズを調べる(整数型));
印字("付号なし整数型(unsigned int)のサイズ= %d byte\n",サイズを調べる(付号なし整数型));
印字("半整数型(short int)のサイズ= %d byte\n",サイズを調べる(半整数型));
印字("長い整数型(long int)のサイズ= %d byte\n",サイズを調べる(長い整数型));
印字("実数型(float)のサイズ= %d byte\n",サイズを調べる(実数型));
印字("倍精度型(double)のサイズ= %d byte\n",サイズを調べる(倍精度型));
印字("長い倍精度型(long double)のサイズ= %d byte\n",サイズを調べる(長い倍精度型));
印字("整数ベクトル計算型(__m128i)のサイズ= %u byte\n",サイズを調べる(整数ベクトル計算型));
印字("実数ベクトル計算型(__m128)のサイズ= %u byte\n",サイズを調べる(実数ベクトル計算型));
正常終了;
}
例題W-5 PowerShell上のbcc32cで動作するc_ex5.jc
PowerShell上のbcc32cで取り扱えるようにWSL上で以下のコマンドを実行します。
/*
各型のサイズを求める
*/
#include <stdio.h>
#define __SSE2__
#define __SSE__
#define __MMX__
#include <emmintrin.h> // SSE命令セットのヘッダー
int main() {
printf("文字型(char)のサイズ= %d byte\n",sizeof(char));
printf("符号なし文字型(unsigned char)のサイズ= %d byte\n",sizeof(unsigned char));
printf("整数型(int)のサイズ= %d byte\n",sizeof(int));
printf("付号なし整数型(unsigned int)のサイズ= %d byte\n",sizeof(unsigned int));
printf("半整数型(short int)のサイズ= %d byte\n",sizeof(short int));
printf("長い整数型(long int)のサイズ= %d byte\n",sizeof(long int));
printf("実数型(float)のサイズ= %d byte\n",sizeof(float));
printf("倍精度型(double)のサイズ= %d byte\n",sizeof(double));
printf("長い倍精度型(long double)のサイズ= %d byte\n",sizeof(long double));
printf("整数ベクトル計算型(__m128i)のサイズ= %u byte\n",sizeof(__m128i));
printf("実数ベクトル計算型(__m128)のサイズ= %u byte\n",sizeof(__m128));
return 0;
}
例題W-5 PowerShell上のc_ex5.jcの展開したもの
また、PowerShell上のbcc32cでc_ex5.cをコンパイルして実行させた結果を以下に示します。
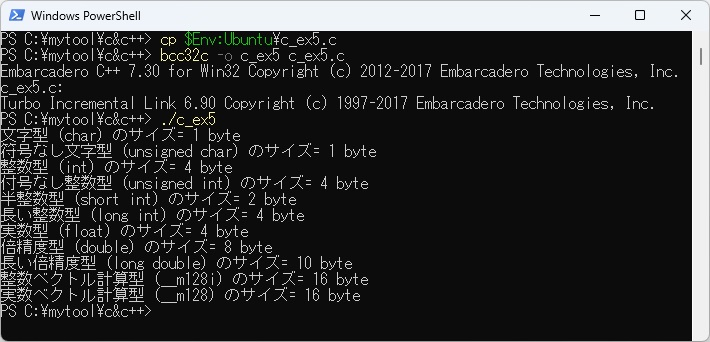
gcc(11.3.0)とbcc32c(7.30)ではlong int、long doubleでサイズが異なることが分かります。
次の例は、初心者に分かりにくいといわれるポインタという概念について、日本語定義でどのくらい分かりにくさを軽減できるのかを試行してみました。
C言語のポインタは「*」(アスタリスク)という記号を用いて表していますが、この記号は算術演算子の掛け算という意味とポインタの両方の意味で使われています。また、ポインタの仲間でアドレスを表す「&」演算子というものがありますが、これもビットごとの論理積演算子と両方の意味を持たせてあります。(注:通常のAND演算子は&&です)
このポインタを使った変数の宣言文と、その変数を使う場合、またアドレス演算子との関係などがC言語の初心者にとっては頭が痛いのではないかと思います。そこで整理してみますと、まず通常の整数型の変数nanjaを宣言すると、以下のように記述されます。
int nanja;
この「nanja」という名前は、別の言い方をすると一つの記憶場所の番地であるとも言えます。しかし、「nanja」に対しての演算はあくまでも「nanja」番地ではなく、番地の中味に対して行われると考えられます。また、「nanja」番地自身を取り出すには「&nanja」と書くようにC言語では定められています。一方、ポインタを使用した場合には、次のように宣言されます。
int *monja;
これは「monja」番地という記憶場所の中味が、さらにまた別の記憶場所の番地を示すということになります(これは専門的には間接アドレッシングと呼ばれております)。そして、その間接的に示された番地の中味が整数型の値であると処理系に解釈されます。従って「monja」番地が示す間接的な番地の中味に何か整数の値を代入したい場合には、例えば次のような書き方をします。
*monja = 123;
このように宣言では「monja」が間接的な番地であるとするのに「*」を使っていますが、間接的な番地で示される中味の値を取り出したり、書き換えたりする場合にもやはり「*」の記号を使っています。
慣れた方には違和感がないのかもしれませんが、このあたりの記号の使い方が、どうもしっくりとなじまないのは筆者だけでしょうか。そこで今回の日本語定義では「*」については、間接的な「整数型への番地|」、間接的な番地の「中味|」というそれぞれ3文字の文字列に置き換えて使ってみました。
また、「&」については日本語定義では「参照|」という文字列に置き換えております。これはC++言語編にも出てくる参照型というものとの整合性を考えてみました。
次の例は現在の時刻を読み込んで、日本流の「刻」として表示するWSLとPowerShellのプログラムです。振り分けに「switch」文を使用し、「&」、「*」を日本語定義で「参照|」、「整数型への番地|」、「中味|」と置き換えてあります。
/* 現在の刻を表示する */
#include <stdio.h>
#include <time.h>
#日本語定義 文字型 "char"
#日本語定義 型なし "void"
#日本語定義 整数型 "int"
#日本語定義 整数型への番地| "int *"
#日本語定義 構造体 "struct"
#日本語定義 中味| "*"
#日本語定義 参照| "&"
#日本語定義 はじまり "main"
#日本語定義 通常終了 "return 0"
#日本語定義 異常終了 "return 1"
#日本語定義 振り分け "switch"
#日本語定義 場合分け "case"
#日本語定義 振り分け終了 "break"
#日本語定義 どれでもない "default"
#日本語定義 印字 "printf"
#日本語定義 現在の時間を読み出す "time(NULL)"
#日本語定義 今の時間 "current_time"
#日本語定義 ロ-カル時間 "local_time"
#日本語定義 時間 "local_time->tm_hour"
#日本語定義 時間型 "time_t"
#日本語定義 ロ-カル時間型 "tm"
#日本語定義 ローカル時間に変換 "localtime"
#日本語定義 子刻 "0"
#日本語定義 丑刻 "1"
#日本語定義 寅刻 "2"
#日本語定義 卯刻 "3"
#日本語定義 辰刻 "4"
#日本語定義 巳刻 "5"
#日本語定義 午刻 "6"
#日本語定義 未刻 "7"
#日本語定義 申刻 "8"
#日本語定義 酉刻 "9"
#日本語定義 戌刻 "10"
#日本語定義 亥刻 "11"
#日本語定義 今の刻
#日本語定義 文字列一
整数型 はじまり(型なし)
{
整数型への番地|今の刻;
文字型 文字列一[] = "今の刻は";
時間型 今の時間 = 現在の時間を読み出す;
// 現在の時刻が正しく取得できたか確認
if (今の時間 == -1) {
印字("現在の時刻の取得に失敗しました。\n");
異常終了;
}
構造体 ロ-カル時間型 中味|ロ-カル時間 = ローカル時間に変換(参照|今の時間);
中味|今の刻 = 時間 / 2 ;
印字("%s", 参照|文字列一[0]);
振り分け(中味|今の刻) {
場合分け 子刻: { 印字("子刻(ねのこく)です。\n"); }; 振り分け終了;
場合分け 丑刻: { 印字("丑刻(うしのこく)です。\n"); }; 振り分け終了;
場合分け 寅刻: { 印字("寅刻(とらのこく)です。\n"); }; 振り分け終了;
場合分け 卯刻: { 印字("卯刻(うのこく)です。\n"); }; 振り分け終了;
場合分け 辰刻: { 印字("辰刻(たつのこく)です。\n"); }; 振り分け終了;
場合分け 巳刻: { 印字("巳刻(みのこく)です。\n"); }; 振り分け終了;
場合分け 午刻: { 印字("午刻(うまのこく)です。\n"); }; 振り分け終了;
場合分け 未刻: { 印字("未刻(ひつじのこく)です。\n"); }; 振り分け終了;
場合分け 申刻: { 印字("申刻(さるのこく)です。\n"); }; 振り分け終了;
場合分け 酉刻: { 印字("酉刻(とりのこく)です。\n"); }; 振り分け終了;
場合分け 戌刻: { 印字("戌刻(いぬのこく)です。\n"); }; 振り分け終了;
場合分け 亥刻: { 印字("亥刻(いのこく)です。\n"); }; 振り分け終了;
どれでもない: { 印字("時計の異常です。\n"); }; 振り分け終了;
}
通常終了;
}
例題W-6 WSL上のgccで動作するc_ex6w.jc
/* 現在の刻を表示する */
#include <stdio.h>
#include <time.h>
int main(void)
{
int *jp_str_0;
char jp_str_1[] = "今の刻は";
time_t current_time = time(NULL);
// 現在の時刻が正しく取得できたか確認
if (current_time == -1) {
printf("現在の時刻の取得に失敗しました。\n");
return 1;
}
struct tm *local_time = localtime(¤t_time);
*jp_str_0 = local_time->tm_hour / 2 ;
printf("%s", &jp_str_1[0]);
switch(*jp_str_0) {
case 0: { printf("子刻(ねのこく)です。\n"); }; break;
case 1: { printf("丑刻(うしのこく)です。\n"); }; break;
case 2: { printf("寅刻(とらのこく)です。\n"); }; break;
case 3: { printf("卯刻(うのこく)です。\n"); }; break;
case 4: { printf("辰刻(たつのこく)です。\n"); }; break;
case 5: { printf("巳刻(みのこく)です。\n"); }; break;
case 6: { printf("午刻(うまのこく)です。\n"); }; break;
case 7: { printf("未刻(ひつじのこく)です。\n"); }; break;
case 8: { printf("申刻(さるのこく)です。\n"); }; break;
case 9: { printf("酉刻(とりのこく)です。\n"); }; break;
case 10: { printf("戌刻(いぬのこく)です。\n"); }; break;
case 11: { printf("亥刻(いのこく)です。\n"); }; break;
default: { printf("時計の異常です。\n"); }; break;
}
return 0;
}
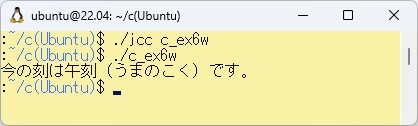
例題W-6 WSL上のc_ex6w.jcの展開したもの
このプログラムをコンパイルして実行させた結果を以下に示します。
/* 現在の刻を表示する */
#include <stdio.h>
#include <dos.h>
#日本語定義 文字型 "char"
#日本語定義 型なし "void"
#日本語定義 整数型 "int"
#日本語定義 構造体 "struct"
#日本語定義 番地| "*"
#日本語定義 中味| "*"
#日本語定義 参照| "&"
#日本語定義 はじまり "main"
#日本語定義 通常終了 "return 0"
#日本語定義 振り分け "switch"
#日本語定義 場合分け "case"
#日本語定義 振り分け終了 "break"
#日本語定義 どれでもない "default"
#日本語定義 印字 "printf"
#日本語定義 現在の時間を読み出す "gettime"
#日本語定義 時間 "ti_hour"
#日本語定義 時分秒型 "time"
#日本語定義 子刻 "0"
#日本語定義 丑刻 "1"
#日本語定義 寅刻 "2"
#日本語定義 卯刻 "3"
#日本語定義 辰刻 "4"
#日本語定義 巳刻 "5"
#日本語定義 午刻 "6"
#日本語定義 未刻 "7"
#日本語定義 申刻 "8"
#日本語定義 酉刻 "9"
#日本語定義 戌刻 "10"
#日本語定義 亥刻 "11"
#日本語定義 今の刻
#日本語定義 今の時間
#日本語定義 時刻の集合
#日本語定義 文字列一
整数型 はじまり(型なし)
{
整数型 今の時間;
整数型 番地|今の刻;
文字型 文字列一[] = "今の刻は";
構造体 時分秒型 時刻の集合;
現在の時間を読み出す( 参照|時刻の集合);
今の時間 = 時刻の集合.時間 / 2 ;
今の刻 = 参照|今の時間;
印字("%s", 参照|文字列一[0]);
振り分け(中味|今の刻) {
場合分け 子刻: { 印字("子刻(ねのこく)です。\n"); }; 振り分け終了;
場合分け 丑刻: { 印字("丑刻(うしのこく)です。\n"); }; 振り分け終了;
場合分け 寅刻: { 印字("寅刻(とらのこく)です。\n"); }; 振り分け終了;
場合分け 卯刻: { 印字("卯刻(うのこく)です。\n"); }; 振り分け終了;
場合分け 辰刻: { 印字("辰刻(たつのこく)です。\n"); }; 振り分け終了;
場合分け 巳刻: { 印字("巳刻(みのこく)です。\n"); }; 振り分け終了;
場合分け 午刻: { 印字("午刻(うまのこく)です。\n"); }; 振り分け終了;
場合分け 未刻: { 印字("未刻(ひつじのこく)です。\n"); }; 振り分け終了;
場合分け 申刻: { 印字("申刻(さるのこく)です。\n"); }; 振り分け終了;
場合分け 酉刻: { 印字("酉刻(とりのこく)です。\n"); }; 振り分け終了;
場合分け 戌刻: { 印字("戌刻(いぬのこく)です。\n"); }; 振り分け終了;
場合分け 亥刻: { 印字("亥刻(いのこく)です。\n"); }; 振り分け終了;
どれでもない: { 印字("時計の異常です。\n"); }; 振り分け終了;
}
通常終了;
}
例題W-5 PowerShell上のbcc32cで動作するc_ex6.jc
PowerShell上のbcc32cで取り扱えるようにWSL上で以下のコマンドを実行します。
/* 現在の刻を表示する */
#include <stdio.h>
#include <dos.h>
int main(void)
{
int jp_str_1;
int *jp_str_0;
char jp_str_3[] = "今の刻は";
struct time jp_str_2;
gettime( &jp_str_2);
jp_str_1 = jp_str_2.ti_hour / 2 ;
jp_str_0 = &jp_str_1;
printf("%s", &jp_str_3[0]);
switch(*jp_str_0) {
case 0: { printf("子刻(ねのこく)です。\n"); }; break;
case 1: { printf("丑刻(うしのこく)です。\n"); }; break;
case 2: { printf("寅刻(とらのこく)です。\n"); }; break;
case 3: { printf("卯刻(うのこく)です。\n"); }; break;
case 4: { printf("辰刻(たつのこく)です。\n"); }; break;
case 5: { printf("巳刻(みのこく)です。\n"); }; break;
case 6: { printf("午刻(うまのこく)です。\n"); }; break;
case 7: { printf("未刻(ひつじのこく)です。\n"); }; break;
case 8: { printf("申刻(さるのこく)です。\n"); }; break;
case 9: { printf("酉刻(とりのこく)です。\n"); }; break;
case 10: { printf("戌刻(いぬのこく)です。\n"); }; break;
case 11: { printf("亥刻(いのこく)です。\n"); }; break;
default: { printf("時計の異常です。\n"); }; break;
}
return 0;
}
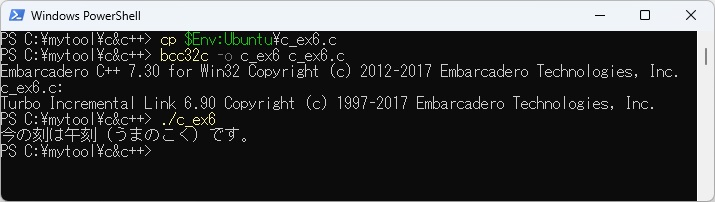
例題W-5PowerShell上のc_ex6.jcの展開したもの
また、PowerShell上のbcc32cでc_ex6.cをコンパイルして実行させた結果を以下に示します。
次の例は共用体を使用した例で8/4バイト整数、4バイト実数、16/10バイト実数について共用体で宣言した変数に値を代入したものです。 共用体により、単一の記憶領域内で異なる種類のデータを処理することができるようになります。
/* 共用体を使用した例 */
#include <stdio.h>
#include <float.h>
#define lputs1(str) printf(" %ld\n",str)
#define lputs2(str) printf(" %3.7f\n",str)
#define lputs3(str) printf(" %3.19Lf\n",str)
#日本語定義 文字型 "char"
#日本語定義 型なし "void"
#日本語定義 整数型 "int"
#日本語定義 長い整数型 "long int"
#日本語定義 実数型 "float"
#日本語定義 長い倍精度型 "long double"
#日本語定義 構造体 "struct"
#日本語定義 共用体 "union"
#日本語定義 型の定義 "typedef"
#日本語定義 はじまり "main"
#日本語定義 通常終了 "return 0"
#日本語定義 印字一 "lputs1"
#日本語定義 印字二 "lputs2"
#日本語定義 印字三 "lputs3"
#日本語定義 整数部分
#日本語定義 実数部分
#日本語定義 長い実数部分
#日本語定義 どちらでも共用できます型
#日本語定義 どちらでも
型の定義 共用体 {
長い整数型 整数部分;
実数型 実数部分;
長い倍精度型 長い実数部分;
} どちらでも共用できます型;
整数型 はじまり(型なし)
{
どちらでも共用できます型 どちらでも;
どちらでも.整数部分 = 3141592653589793238;
印字一(どちらでも.整数部分);
どちらでも.実数部分 = 3.14159265358979323846;
印字二(どちらでも.実数部分);
どちらでも.長い実数部分 = 3.14159265358979323846L;
印字三(どちらでも.長い実数部分);
通常終了;
}
例題W-7 WSL上のgccで動作するc_ex7w.jc
/* 共用体を使用した例 */
#include <stdio.h>
#include <float.h>
#define lputs1(str) printf(" %ld\n",str)
#define lputs2(str) printf(" %3.7f\n",str)
#define lputs3(str) printf(" %3.19Lf\n",str)
typedef union {
long int jp_str_0;
float jp_str_1;
long double jp_str_2;
} jp_str_3;
int main(void)
{
jp_str_3 jp_str_4;
jp_str_4.jp_str_0 = 3141592653589793238;
lputs1(jp_str_4.jp_str_0);
jp_str_4.jp_str_1 = 3.14159265358979323846;
lputs2(jp_str_4.jp_str_1);
jp_str_4.jp_str_2 = 3.14159265358979323846L;
lputs3(jp_str_4.jp_str_2);
return 0;
}
例題W-7 WSL上のc_ex7w.jcの展開したもの
このプログラムをコンパイルして実行させた結果を以下に示します。
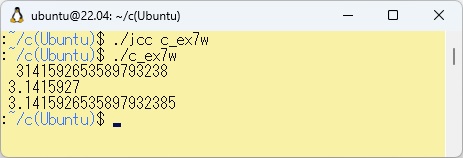
/* 共用体を使用した例 */
#include <stdio.h>
#include <float.h>
#define lputs1(str) printf(" %ld\n",str)
#define lputs2(str) printf(" %3.7f\n",str)
#define lputs3(str) printf(" %3.16Lf\n",str)
#日本語定義 文字型 "char"
#日本語定義 型なし "void"
#日本語定義 整数型 "int"
#日本語定義 長い整数型 "long int"
#日本語定義 実数型 "float"
#日本語定義 長い倍精度型 "long double"
#日本語定義 構造体 "struct"
#日本語定義 共用体 "union"
#日本語定義 型の定義 "typedef"
#日本語定義 はじまり "main"
#日本語定義 通常終了 "return 0"
#日本語定義 印字一 "lputs1"
#日本語定義 印字二 "lputs2"
#日本語定義 印字三 "lputs3"
#日本語定義 整数部分
#日本語定義 実数部分
#日本語定義 長い実数部分
#日本語定義 どちらでも共用できます型
#日本語定義 どちらでも
型の定義 共用体 {
長い整数型 整数部分;
実数型 実数部分;
長い倍精度型 長い実数部分;
} どちらでも共用できます型;
整数型 はじまり(型なし)
{
どちらでも共用できます型 どちらでも;
どちらでも.整数部分 = 314159265;
印字一(どちらでも.整数部分);
どちらでも.実数部分 = 3.14159265358979323846;
印字二(どちらでも.実数部分);
どちらでも.長い実数部分 = 3.14159265358979323846;
印字三(どちらでも.長い実数部分);
通常終了;
}
例題W-7 PowerShell上のbcc32cで動作するc_ex7.jc
PowerShell上のbcc32cで取り扱えるようにWSL上で以下のコマンドを実行します。
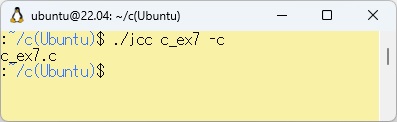
/* 共用体を使用した例 */
#include <stdio.h>
#include <float.h>
#define lputs1(str) printf(" %ld\n",str)
#define lputs2(str) printf(" %3.7f\n",str)
#define lputs3(str) printf(" %3.16Lf\n",str)
typedef union {
long int jp_str_0;
float jp_str_1;
long double jp_str_2;
} jp_str_3;
int main(void)
{
jp_str_3 jp_str_4;
jp_str_4.jp_str_0 = 314159265;
lputs1(jp_str_4.jp_str_0);
jp_str_4.jp_str_1 = 3.14159265358979323846;
lputs2(jp_str_4.jp_str_1);
jp_str_4.jp_str_2 = 3.14159265358979323846;
lputs3(jp_str_4.jp_str_2);
return 0;
}
例題W-7 PowerShell上のc_ex7.jcの展開したもの
また、PowerShell上のbcc32cでc_ex7.cをコンパイルして実行させた結果を以下に示します。
次の例題は外部宣言により、ほかのファイル内で定義された関数を呼び出すということをやってみます。この例として任意の桁数、πの値を計算するプログラムを書いてみます。これは「C─言語とプログラミング─」という本に出ているプログラムを参考にして日本語を多めに書いてみました。
基本的なアルゴリズムとしては古くから知られているマチン(イギリス人 J.Machin 1680-1752)の公式と呼ばれる式が使われております。ちなみに2021年夏、スイスのグラウビュンデン応用大学のスーパーコンピューターが62兆8318億5307万1796桁というギネス世界記録を達成したと報道されました。 マチンの公式を用いたこのプログラムについて興味のある方は、機会があれば同書をご覧いただければ詳しく分かると思います。
今回のプログラムは二つに分かれていて、一つははじまり(main)とマチンの公式を使うメイン関数の部分(c_ex8-1.jc)です。もう一つのファイルは、長い配列の加減除算などを処理する関数郡(c_ex8-2.jc)から成っています。それぞれ別々に翻訳(コンパイル)しておき、後から次のようなコマンドで結合します。ここでは、メイン関数の部分を以下に示します。
/* マチンの公式を使用して、任意の桁数πの値を計算するプログラム */
#include <stdio.h>
#define lputs1 printf(" ")
#define lputs2 printf("\n ")
#日本語定義 型なし "void"
#日本語定義 短い整数型 "unsigned char"
#日本語定義 整数型 "int"
#日本語定義 反復 "for"
#日本語定義 繰り返し "while"
#日本語定義 もし "if"
#日本語定義 それ以外 "else"
#日本語定義 外部定義 "extern"
#日本語定義 はじまり "main"
#日本語定義 通常終了 "return 0"
#日本語定義 戻る "return"
#日本語定義 印字 "printf"
#日本語定義 剰余計算 "%%"
#日本語定義 印字一 "lputs1"
#日本語定義 印字二 "lputs2"
#日本語定義 基数 "10"
#日本語定義 配列の最大値 "200010"
#日本語定義 求める桁数 "200000"
#日本語定義 作業用配列一
#日本語定義 作業用配列二
#日本語定義 πの結果
#日本語定義 長い配列の割り算 "lng_dim_div"
#日本語定義 長い配列の加算 "lng_dim_add"
#日本語定義 長い配列の減算 "lng_dim_sub"
#日本語定義 非ゼロの位置を見つける "nzero_fnd"
#日本語定義 初期化 "init"
#日本語定義 反復数
外部定義 型なし 長い配列の減算( 短い整数型[], 短い整数型[], 短い整数型[] );
外部定義 型なし 長い配列の加算( 短い整数型[], 短い整数型[], 短い整数型[] );
外部定義 型なし 長い配列の割り算( 短い整数型[], 短い整数型[], 整数型, 整数型 );
外部定義 型なし 初期化( 短い整数型[], 整数型 );
外部定義 整数型 非ゼロの位置を見つける( 短い整数型[], 整数型 );
整数型 はじまり(型なし)
{
短い整数型 作業用配列一[配列の最大値+1],
作業用配列二[配列の最大値+1],
πの結果[配列の最大値+1];
整数型 反復数;
型なし マチンの逆正接演算( 短い整数型[], 整数型, 整数型 );
マチンの逆正接演算( 作業用配列一, 16, 5 );
マチンの逆正接演算( 作業用配列二, 4, 239 );
長い配列の減算( πの結果, 作業用配列一, 作業用配列二 );
印字( "%d.", (整数型)πの結果[0] );
反復 ( 反復数 = 1; 反復数 <= 求める桁数; 反復数++ ) {
印字( "%d", (整数型)πの結果[反復数] );
もし ( 反復数 剰余計算 10 == 0 ) 印字一;
もし ( 反復数 剰余計算 50 == 0 ) 印字二;
}
通常終了;
}
#日本語定義 マチンの逆正接演算
#日本語定義 かけ算定数
#日本語定義 級数定数
#日本語定義 正接変数
#日本語定義 配列引数
#日本語定義 非ゼロ位置
型なし マチンの逆正接演算( 配列引数, かけ算定数, 正接変数 )
短い整数型 配列引数[];
整数型 かけ算定数, 正接変数;
{
短い整数型 作業用配列一[配列の最大値+1], 作業用配列二[配列の最大値+1];
整数型 非ゼロ位置, 級数定数 = 3;
初期化( 配列引数, 0 );
初期化( 作業用配列一, かけ算定数 );
長い配列の割り算( 作業用配列一, 作業用配列一, 正接変数, 0 );
非ゼロ位置 = 非ゼロの位置を見つける( 作業用配列一, 0 );
長い配列の加算( 配列引数, 配列引数, 作業用配列一 );
繰り返し( 非ゼロ位置 <= 配列の最大値 ) {
長い配列の割り算( 作業用配列一, 作業用配列一, 正接変数, 非ゼロ位置 );
長い配列の割り算( 作業用配列一, 作業用配列一, 正接変数, 非ゼロ位置 );
長い配列の割り算( 作業用配列二, 作業用配列一, 級数定数, 非ゼロ位置 );
もし ( 級数定数 剰余計算 4 == 1 )
長い配列の加算( 配列引数, 配列引数, 作業用配列二 );
それ以外
長い配列の減算( 配列引数, 配列引数, 作業用配列二 );
非ゼロ位置 = 非ゼロの位置を見つける( 作業用配列一, 非ゼロ位置 );
級数定数 += 2;
}
}
例題W-8(c_ex8-1.jcのみ)
今回は、小数点以下20万桁を求めることとします。また、記憶領域を節約するために、一つの配列について0から9までの加減乗除の計算ですから、配列をint型(4バイト)ではなく、 短い整数型としてunsigend char型(1バイト)で計算をしています。
/* マチンの公式を使用して、任意の桁数πの値を計算するプログラム */
#include <stdio.h>
#define lputs1 printf(" ")
#define lputs2 printf("\n ")
extern void lng_dim_sub( unsigned char[], unsigned char[], unsigned char[] );
extern void lng_dim_add( unsigned char[], unsigned char[], unsigned char[] );
extern void lng_dim_div( unsigned char[], unsigned char[], int, int );
extern void init( unsigned char[], int );
extern int nzero_fnd( unsigned char[], int );
int main(void)
{
unsigned char jp_str_0[200010+1],
jp_str_1[200010+1],
jp_str_2[200010+1];
int jp_str_3;
void jp_str_4( unsigned char[], int, int );
jp_str_4( jp_str_0, 16, 5 );
jp_str_4( jp_str_1, 4, 239 );
lng_dim_sub( jp_str_2, jp_str_0, jp_str_1 );
printf( "%d.", (int)jp_str_2[0] );
for ( jp_str_3 = 1; jp_str_3 <= 200000; jp_str_3++ ) {
printf( "%d", (int)jp_str_2[jp_str_3] );
if ( jp_str_3 % 10 == 0 ) lputs1;
if ( jp_str_3 % 50 == 0 ) lputs2;
}
return 0;
}
void jp_str_4( jp_str_8, jp_str_5, jp_str_7 )
unsigned char jp_str_8[];
int jp_str_5, jp_str_7;
{
unsigned char jp_str_0[200010+1], jp_str_1[200010+1];
int jp_str_9, jp_str_6 = 3;
init( jp_str_8, 0 );
init( jp_str_0, jp_str_5 );
lng_dim_div( jp_str_0, jp_str_0, jp_str_7, 0 );
jp_str_9 = nzero_fnd( jp_str_0, 0 );
lng_dim_add( jp_str_8, jp_str_8, jp_str_0 );
while( jp_str_9 <= 200010 ) {
lng_dim_div( jp_str_0, jp_str_0, jp_str_7, jp_str_9 );
lng_dim_div( jp_str_0, jp_str_0, jp_str_7, jp_str_9 );
lng_dim_div( jp_str_1, jp_str_0, jp_str_6, jp_str_9 );
if ( jp_str_6 % 4 == 1 )
lng_dim_add( jp_str_8, jp_str_8, jp_str_1 );
else
lng_dim_sub( jp_str_8, jp_str_8, jp_str_1 );
jp_str_9 = nzero_fnd( jp_str_0, jp_str_9 );
jp_str_6 += 2;
}
}
例題W-8を展開したもの(c_ex8-1.cのみ)
このプログラムをコンパイルして実行させた最初の部分と最後の部分の結果を以下に示します。
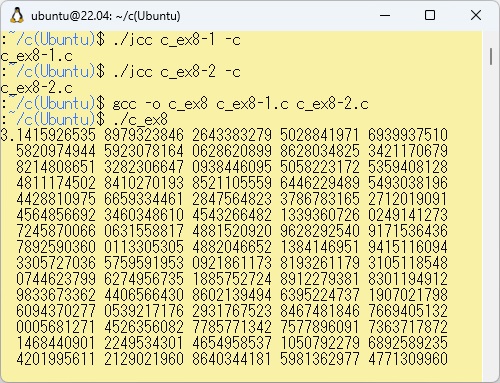
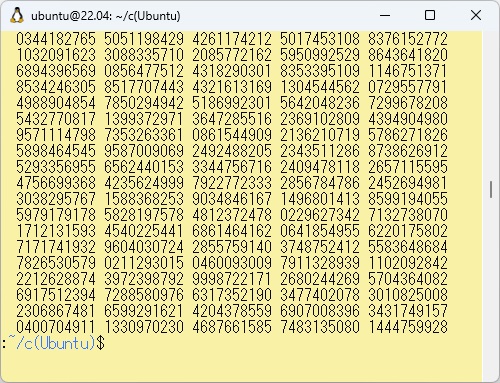
PowerShellのコマンドでWSL上のc_ex8-1.cとc_ex8-2をコピーし、それぞれコンパイル、リンクしてc_ex8.exeが作成されます。 これを実行させた最初の部分と最後の部分の結果を以下に示します。
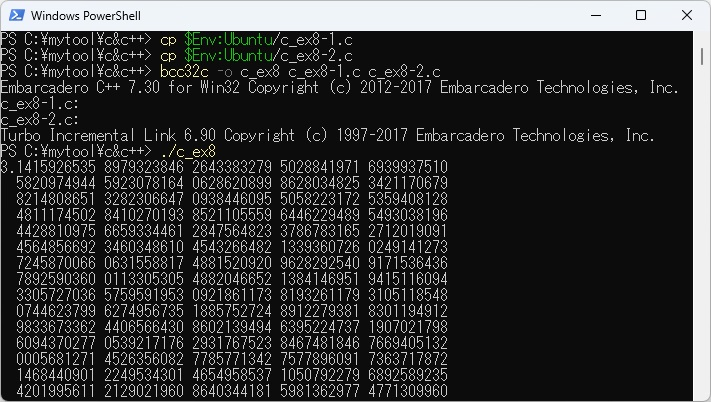
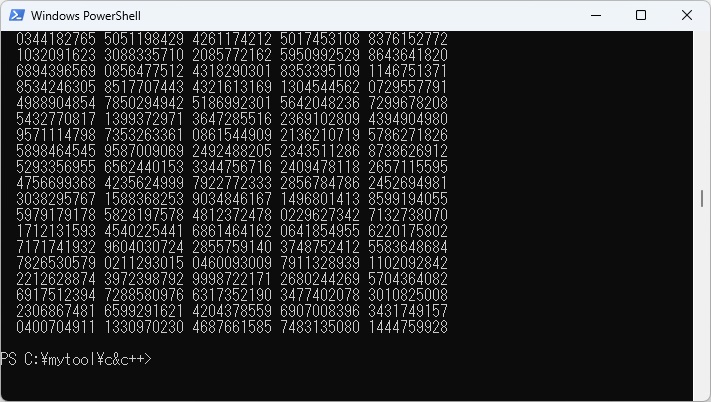
日本語カスタマイザーを利用してC言語を翻訳(コンパイル)するときに、プログラム中に文法的な問題があると警告メッセージやエラーメッセージが表示されます。 このときにjp_str_*(*は数字)についてのエラー情報が出た場合、このjp_str_*とソースコード中の日本語文字列がどのように対応するのかが分からないとデバッグしにくいことが挙げられます。 もっともエラーが出た行番号の情報は出力されますので、ソースコード上でどの行に問題があるのかは分かります。
このようなデバッグ状況に対処する方法としては、日本語カスタマイザーが出力するjc_rule2.lexファイルが残っていますので、この中の規則記述部分を見ることによって、日本語文字列とそれに対応するjp_str_*がどれかということが分かります。 多少手数はかかりますが、デバッグについて全く対処できないというわけではないと思います。
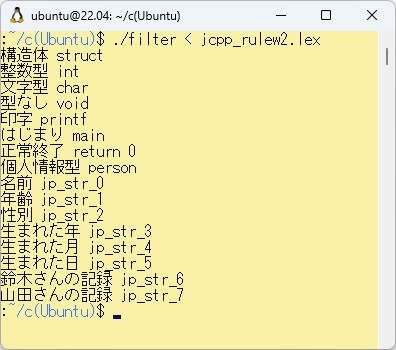
ここでは「filter」というFLEXを用いた簡単なデバッグ用のツールを作ってみました。中味はjc_rule2.lexの規則記述部分だけを取り出して、表示するというものです。例題W-3において日本語カスタマイザーが出力したjc_rule2.lexを読み込ませた動作結果を以下に示します。 このような簡単なツールを作ることで、日本語と実際に使われている予約語や変数を対応させることができるのではないかと思います。
WindowsのWSLで日本語カスタマイザーを使うメリットとしては、Windows版のFLEX(2.5.4)ではUTF-8コードで日本語を使えない上、SHIFT-JISコードでも制約があって、処理が複雑になってしまうことがありました。 その点、WSLのFLEX(2.6.4)では、UTF-8コードで簡単に日本語を処理できるので、日本語カスタマイザーをつくるのに大変便利です。
gccとbcc32cの今回のバージョンでは、変数をプログラム中に直接UTF-8コードで日本語を書いても、gccでは問題なくコンパイルできました。 一方、bcc32c(V7.30)では一部の全角日本語で書くとコンパイラエラーが出るため、変数はすべて日本語カスタマイザーで日本語定義をしていますが、 C++builder community editionのbcc32cのバージョンV7.70(制限付きフリー入手可能)では、変数に直接UTF-8コードで日本語を書いても問題なくコンパイルできることを確認しています。 同様に、V7.70でこのページのプログラムは動作確認をしています。また、V7.30ではc_ex5.cの#includeファイルは、<emmintrin.h>ですが、V7.70では<immintrin.h>を利用ができ、_SSE2__、__SSE__、__MMX__の定義は不要です。
前回までは、インラインアセンブラの簡単なプログラムを載せていましたが、WSLやWindowsのC言語でインラインアセンブラの記述が、だんだんと複雑になってきましたので、今回は割愛させていだきました。
今回はAIを一部アシスタントとして活用しました。現在AIによってプログラミングの環境が劇的に変化しています。 AIに、こういうプログラムをつくってくれと指示すると、かなり正確なコードを提示してくれたりするようになってきました。 中には指示の仕方によっては、動作しないものをありますが、今後は膨大なデータベースを持っているAIの助けを借りて、プログラミングを考えるということが一般的になってくるのではないでしょうか。


参考図書&参考サイト
UNIXプログラミング環境 Brian W.Kernighan Rob Pike 石田晴久監訳 アスキー出版局 1985
プログラミング言語C B.W. カーニハン D.M. リッチー 石田晴久訳 共立出版社 1981
UNIX 石田晴久著 共立出版社 1983
AIサイト ChatGPT