
(ubuntu 13.10/14.04LTS版)
Windows版のFLEX日本語活用編に引き続き、Debian Linux系OSであるubuntu( ぅぉー ぶーん つぅーと発音するようです。ubuntuの意味は、南アフリカの倫理的な概念で、「他者への思いやり」だそうです)上で、Windowsと同じようにFLEXを用いて日本語文書処理をやってみたいと思います。(FLEXについての概説はWindows版の方に記載しています)FLEXはもともとUNIXというOS上で作られたLEXというツールの後継にあたりますので、UNIXの流れをくむUbuntuの方がより洗練されたFLEXの使い方ができるのではないでしょうか。また、ubuntuは優秀なOSであるだけではなく、誰でもフリーで入手することがてきます。
ここではubuntu13.10(14.04LTS)版というOS上で、FLEX(version 2.5.4a)をインストールしました。それを端末(terminal)というCUIを利用して動かしてみます。FLEXを動かすにはC言語の処理系が必要となりますが、ubuntu_13.10ではOSに標準で装備されているようです。また、ubuntuでは古いバージョンのFLEXをインターネットから入手する必要があります。 FLEX(version 2.5.4a)の場合には、「flex-old_2.5.4a-7_i386.deb」というパッケージをネット上のリポジトリ(ファイル保管倉庫)から探してインストールしました。
ubuntu-OSもバージョンによって正式なサポート期間が決まっていて、現在ubuntu 14.04LTS版では2019年の4月までサポート予定です。14.04LTS版でも以下の練習問題の動作確認を行っています。
FLEXのプログラムは一度C言語に変換されます。それをC言語処理系によって翻訳することにより、プログラムを実行することができます。従ってFLEXのプログラムを動かすにはC言語の処理系が必要となりますので、これもubuntuの場合には「sudo apt-get install」などのコマンドにより、gcc(ubuntu 13.10ではV4.8.1/ubuntu 14.04LTSではV4.8.4)というフリーの処理系をインストールしておくことが必要となります。
FLEXの起動確認
例題FU─1 入力ファイルをそのまま出力する
例題FU─2 文字列を変換する(その一)
例題FU─3 文字列を変換する(その二)
例題FU─4 簡単なC言語風日本語プログラムの実行
例題FU─5 FLEX規則を利用してC言語を日本語で記述する
例題FU─6 文字クラスを使った日本語文字処理の基本練習
例題FU─7 FLEXを利用した送り仮名のチェック
例題FU─8 FLEXを利用した簡単な同音異義語のチェック
例題FU─9 FLEXでスタート状態を使った練習
例題FU─10 FLEXを利用した簡単な表記チェッカー
例題FU-11 FLEXでCGIを動かす(その一)
例題FU-12 FLEXでCGIを動かす(その二)
例題FU-13 自動番号の付いた規則をつくる
例題FU-14 FLEX規則を利用してC言語を日本語で記述する(続編)
例題FU-15 FLEXを利用して自動販売機のシミュレーションを行なう
日本語カスタマイザーについて

まずubuntuでterminal(端末)を立ち上げ、FLEXが利用できる作業用フォルダ/ディレクトリに移動します。ここではカレントディレクトリ~/flexという場所を使います。本来はユーザー名やホスト名の後にディレクトリ名が表示されるのですが、ここではわざとユーザー名やホスト名は非表示にしてあります。(GEDITはテーマ色の変更が可能です)
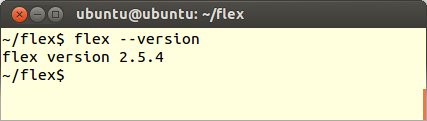
FLEXのインストールを行った後、次のようなコマンド入力をします。(--version または -V)
$flex --version
うまくインストールできている場合には、次のようにバージョン番号が出力されます。
Windows版とのバージョンを合わせるためにも、上記のようなFLEXのバージョンを選びましたが、リポジトリから入手できるバージョンとは異なるかもしれません。もし、うまくFLEXがインストールできない場合には、リポジトリのアドレスが現在サポートされているアドレスかどうかを一度確かめてください。正式なサポートが終了していても、別の場所で管理されていることがありますので、ネットで根気よく調べてみてください。
ここで最初に簡単なFLEXのプログラムを作ってみたいと思います。
GEDITなどで、次のようにプログラムを入力します。
/* FLEX テストプログラム1 */
%{
#define YY_SKIP_YYWRAP
int yywrap( void ) { return(1) ; }
%}
%%
%%
int main()
{
yylex();
return(0);
}
このファイルをtest1.lexという名前で作業用フォルダ/ディレクトリ内に保存します。Windows版のときにはmainの関数をvoid型で定義していますが、ubuntuの場合にはmainの関数をint型で定義して、戻り値をreturn(0)で返すようにしてください。
コマンドプロンプトから次のように入力するか、簡単なシェルスクリプト(バッチファイル)によって自動的にtest1を生成できるようにします。
コマンドプロンプトから入力する場合
$flex test1.lex
$gcc lex.yy.c
$cp a.out test1
簡単なシェルスクリプトlccの内容
#!/bin/bash
flex $1.lex
gcc lex.yy.c
cp a.out $1
exit 0
シェルスクリプトから実行する場合
$./lcc test1
ここではシェルスクリプト(バッチファイル)で実行させてみました。シェルスクリプトは、必ずプログラムとして実行できるアクセス権を与えておかないといけません。このやり方は、ファイル・ブラウザでlccを右クリックしてプロパティを選択します。プロパティ画面の「アクセス権」タブを選択し、「実行権」の項目にある「プログラムとして実行することを許す」にチェックをするだけです。
次にGEDITなどで、次のようなテキストを入力してex1.txtという名前で保存します。
あいうえお
かきくけこ
さしすせそ
たちつてと
なにぬねの
はひふへほ
まみむめも
やゆよ
らりるれろ
わをん
コマンドプロンプトから次のように入力します。
$./test1 < ex1.txtex1.txtの内容がそのまま次のように表示されることを確認します。
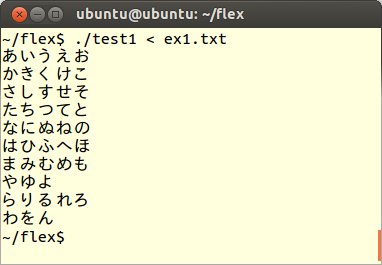
Windows版の日本語文書処理編をまだご覧になっていない方にとっては、これが一体何をするプログラムかということは、まだよく分からないかもしれませんが、これで一応FLEXプログラム環境で、うまく動作するかどうかの確認ができたと思います。
FLEXプログラムでは、大まかに次のような構造になっているようです。
定義や初期Cコード
%%
規則部分
%%
その他Cコード
プログラム中に直接C言語のコードを含める場合には、そのコードを%{と%}の間に含めます。
%{
#define YY_SKIP_YYWRAP
int yywrap( void ) { return(1) ; }
%}
上記%{と%}の間に含まれる二行については、ラッパー関数といわれる定義の部分ですが、ここでは深入りせずに、このように書くということで進めたいと思います。
(詳しくは、yywrapの説明を参照)
また、さまざまな規則は、%%と%%に挟まれた行間に記述し、その他のCコードは二番目の%%の次の行以後に書きます。
int main()
{
yylex();
return(0);
}
上記のCコードについては、その他のCコードにあたる部分ですが、yylex()が実際に字句解析を行うための関数呼び出しです。これはint main( ){ }という関数内に記述しますが、これについてもあまり深入りせずに、ubuntu版ではこのように書くということで先へ進めたいと思います。
次のプログラムはtest1.lexをベースに規則部分の記述の方法について練習します。test1.lexの規則部分に次のような一行を加え、test2.lexという名前で保存します。
/* FLEX テストプログラム2 */
%{
#define YY_SKIP_YYWRAP
int yywrap( void ) { return(1) ; }
%}
%%
"あいうえお" { printf("かきくけこ"); }
%%
int main()
{
yylex();
return(0);
}
このtest2.lexを先ほどのtest1.lexと同様に、バッチファイルを利用してコンパイルし、次のようにex1.txtを読み込むように実行します。
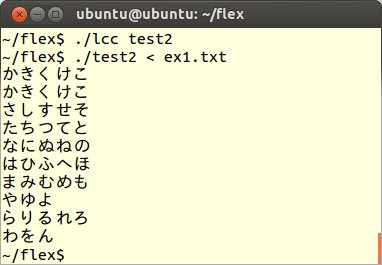
この結果から、規則部分に"あいうえお" {printf("かきくけこ");}と記述すると、ex1.txtファイル中の「あいうえお」という文字列がそっくり「かきくけこ」という文字列に置き換えられて表示されました。つまり、"あいうえお"の後に区切り文字(空白、タブ)をはさんで、{printf("かきくけこ");}と書くと、"あいうえお"という文字列を見つけるたびに、"かきくけこ"と出力せよという規則になります。{ }内にはC言語のプログラムをそのまま書くことができます。printf("かきくけこ");とは文字列「かきくけこ」を出力させるC言語のコードです。
ここで規則部分は必ず行の先頭から記述してください。行頭に空白やタブが入っているとFLEXからエラーメッセージが出ます。
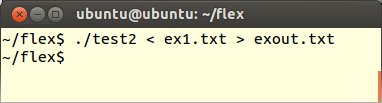
表示された内容をそのまま別のファイルとして保存する場合には、次のようにコマンドプロンプトのリダイレクション機能を利用します。ここでは保存するファイル名をexout.txtとしました。
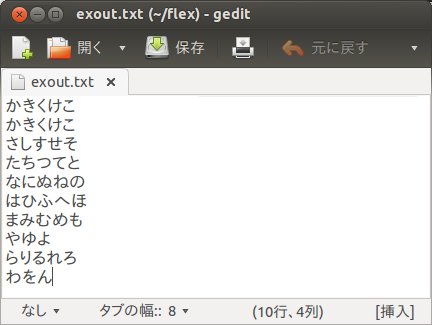
exout.txtの内容をメモ帳で表示させてみます。
また、このFLEXによる規則は入力ファイルの1箇所だけではなく、すべての箇所について適用されます。
次に複数の規則を記述してみます。次のようなFLEXプログラムを書いて、これをtest3.lexとして保存します。
/* FLEX テストプログラム3 */
%{
#define YY_SKIP_YYWRAP
int yywrap( void ) { return(1) ; }
%}
%%
"らりるれろ" { printf("あいうえお"); }
"やゆよ" { printf("わをん"); }
"わをん" { printf("やゆよ"); }
%%
int main()
{
yylex();
return(0);
}
次にGEDITなどで、次のようなテキストを入力してex3.txtという名前で保存します。
らりるれろ
わをん
なにぬねの
らりるれろ
やゆよ
がぎぐげご
たちつてと
ぱぴぷぺぽ
やゆよ
このtest3.lexをコンパイルし、次のようにex3.txtを読み込むように実行します。
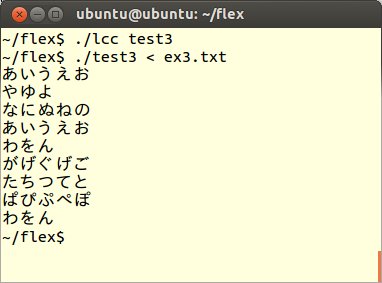
規則部分で指定したように、入力ファイルの内容が変換されたことが分かります。このように複数の規則でも、%%と%%に挟まれた行間に並べて記述することができます。ここではFLEX文法の詳細については立ち入りませんが、より知識を深めたい方は、ダウンロードしたFLEXプログラムに付随するマニュアル/ドキュメント等を参照してください。
次に簡単なC言語風の日本語プログラムをC言語に変換するためのFLEXプログラムを作ってみます。ex4.txtファイルを作成して、以下のように入力、保存しておきます。
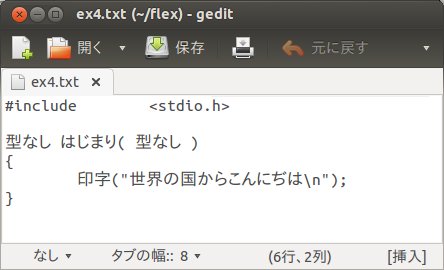
ここで、前回までのFLEXプログラムでは、初期Cコードとしてラッパー関数の定義をそのまま記述しておりましたが、これを別のインクルードファイルflex_test.incに記述します。
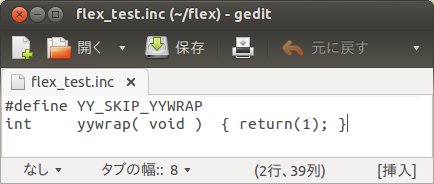
このようにするとFLEXプログラムは、よりすっきり見えるのではないかと思います。これに変換規則を適用させたものをtest4.lexとします。
/*
FLEX テストプログラム4 */
%{
#include "flex_test.inc"
%}
%%
"型なし" { printf("void"); }
"整数型" { printf("int"); }
"はじまり" { printf("main"); }
"印字" { printf("printf"); }
%%
int main()
{
yylex();
return(0);
}
このtest4.lexをコンパイルし、次のようにex4.txtを読み込むように実行します。
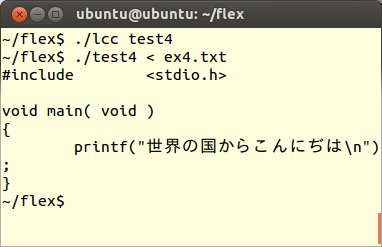
また、この結果をexout.cというファイルにして、C言語の処理系に通せば、立派なプログラムとして動作することも分かります。(C言語処理系のgccでは、オプションを何も指定しなければ、デフォルトでa.outという実行可能ファイルを出力します)
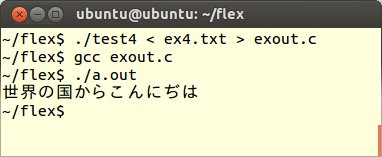
flexやgccにはいくつかのコマンドラインオプション機能があります。-oオプションを指定することにより、出力ファイル名の指定もできますので、今までのシェルスクリプトを以下のように変更します。これでよりすっきりとコンパイル、実行ができるようになると思います。
シェルスクリプトの内容(lcc)
#!/bin/bash
flex -o$1 $1.lex
gcc -o$1 $1.c
exit 0
次に日本語カスタマイザーC言語編からの例題ですが、構造体を使ったC言語風の日本語プログラムをC言語に変換するFLEXプログラムを作ってみます。ex5.txtファイルを作成して、以下のように入力、保存しておきます。
/* 個人情報を印字する */
#include <stdio.h>
構造体 個人情報型 {
文字型 名前[30];
整数型 年齢;
文字型 性別[4];
整数型 生まれた年;
整数型 生まれた月;
整数型 生まれた日;
};
整数型 はじまり(型なし)
{
構造体 個人情報型 鈴木さんの記録 = {"鈴木太郎",46,"男",1963,2,14};
構造体 個人情報型 山田さんの記録 = {"山田花子",35,"男",1974,8,23};
印字("名前=%s\n",鈴木さんの記録.名前);
印字("年齢=%d歳\n",鈴木さんの記録.年齢);
印字("性別=%s\n",鈴木さんの記録.性別);
印字("生年月日=%d年",鈴木さんの記録.生まれた年);
印字("%d月",鈴木さんの記録.生まれた月);
印字("%d日生まれ\n\n",鈴木さんの記録.生まれた日);
印字("名前=%s\n",山田さんの記録.名前);
印字("年齢=%d歳\n",山田さんの記録.年齢);
印字("性別=%s\n",山田さんの記録.性別);
印字("生年月日=%d年",山田さんの記録.生まれた年);
印字("%d月",山田さんの記録.生まれた月);
印字("%d日生まれ\n",山田さんの記録.生まれた日);
通常終了;
}
Windows版のFLEXでは、シフトJISコードの2バイト目が16進数で「5C」のコード(文字ではバックスラッシュ、¥マーク)は、文字としてうまく認識させるときには注意が必要でした。 しかし、ubuntu版では文字コード体系がUTF-8というUNICODEの文字体系が採用されていますので、特に気にしなくても規則のパターンマッチ部分は、日本語で書くことができるようです。 ちなみに、ubuntu13.10のテキストエディタでは、\マークではなくバックスラッシュとして表示されますが、このページではすべて\マークで表しています。
/* FLEX テストプログラム5 */
%{
#include "flex_test.inc"
%}
%%
"型なし" { printf("void"); }
"整数型" { printf("int"); }
"文字型" { printf("char"); }
"はじまり" { printf("main"); }
"通常終了" { printf("return(0)"); }
"印字" { printf("printf"); }
"構造体" { printf("struct"); }
"個人情報型" { printf("person"); }
"名前" { printf("jp_str_1"); }
"年齢" { printf("jp_str_2"); }
"性別" { printf("jp_str_3"); }
"生まれた年" { printf("jp_str_4"); }
"生まれた月" { printf("jp_str_5"); }
"生まれた日" { printf("jp_str_6"); }
"鈴木さんの記録" { printf("jp_str_7"); }
"山田さんの記録" { printf("jp_str_8"); }
%%
int main()
{
yylex();
return(0);
}
このtest5.lexをコンパイルし、ex5.txtを読み込むと次のような結果が表示されます。
/* 個人情報をprintfする */
#include <stdio.h>
struct person {
char jp_str_1[30];
int jp_str_2;
char jp_str_3[4];
int jp_str_4;
int jp_str_5;
int jp_str_6;
};
int main(void)
{
struct person jp_str_7 = {"鈴木太郎",46,"男",1963,2,14};
struct person jp_str_8 = {"山田花子",35,"男",1974,8,23};
printf("jp_str_1=%s\n",jp_str_7.jp_str_1);
printf("jp_str_2=%d歳\n",jp_str_7.jp_str_2);
printf("jp_str_3=%s\n",jp_str_7.jp_str_3);
printf("生年月日=%d年",jp_str_7.jp_str_4);
printf("%d月",jp_str_7.jp_str_5);
printf("%d日生まれ\n\n",jp_str_7.jp_str_6);
printf("jp_str_1=%s\n",jp_str_8.jp_str_1);
printf("jp_str_2=%d歳\n",jp_str_8.jp_str_2);
printf("jp_str_3=%s\n",jp_str_8.jp_str_3);
printf("生年月日=%d年",jp_str_8.jp_str_4);
printf("%d月",jp_str_8.jp_str_5);
printf("%d日生まれ\n",jp_str_8.jp_str_6);
return(0);
}
この結果をexout.cというファイルに保存し、コンパイルして実行結果を確認します。
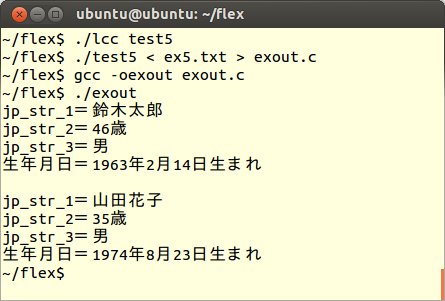
実行結果からも分かるように、実際の(C言語用)日本語カスタマイザーでは、二重引用符(ダブルクォーテーション)で囲まれた文字列は変換しないようにしていますが、今回のテストプログラムでは、すべての文字列について変換規則が適用されています。
ここで、少し文字コードについて触れておきたいと思います。ubuntuのコマンドプロンプトで、GEDITを使用してファイルを保存する場合をここでは想定します。このとき文字コードは通常UTF-8として保存されます。これはUNICODEと呼ばれるコード体系の中でも、日本語文字を3~4バイトで表現することができます。`UTF-8は多国語をエンコードする方法の一つで、UNIXのシステムプログラマーのKen Thompson氏が策定に貢献したことでも有名です。
また、英語圏で通常使用されるアスキー(ascii)コードは、1バイトコードであり、16進数で00~7fですが、UTF-8でもアスキーコードと同じ半角文字は1バイト目に同じコードが割り当てられています。
さらに、日本独自の規格である1バイトカタカナ(半角カタカナ)も、UTF-8ではコードが割り当てられています。
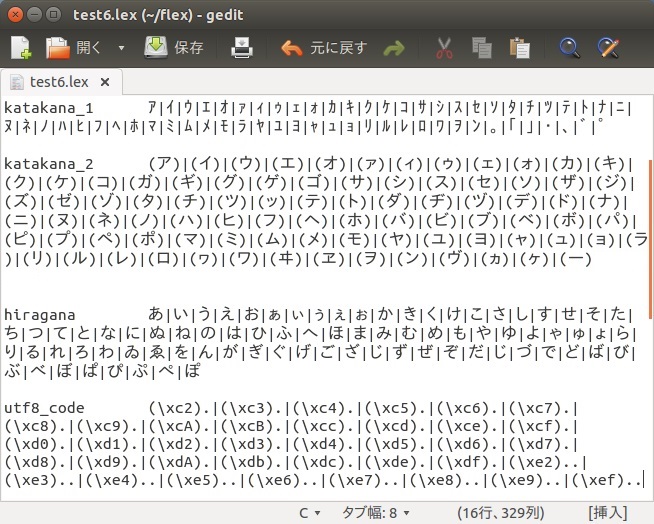
このあたりの様子を理解するためにも、次のようなtest6.lexというFLEXプログラムを書いてみます。ただし、文字クラスと呼ばれる定義部については、一行があまりに長くなり過ぎたため少し見づらいとは思いますが、GEDITの右端折り返しで表示しています。
/* FLEX テストプログラム6 */
%{
#include "flex_test.inc"
#define pr_text printf("%s",yytext)
%}
%%
{katakana_1} { }
[[:alpha:]] { }
[[:digit:]] { }
{katakana_2} { }
{hiragana} { }
{utf8_code} { }
. { }
\n {
pr_text; }
%%
void main()
{
yylex();
}
文字クラスの詳細な文法については、ここでは触れませんが、文字クラスのラベルとそれに対する文字集合を定義できます。test6.lexにおいて、それぞれの意味は次のようなものです。
katakana_1 |
半角カタカナ文字の定義 |
katakana_2 |
全角カタカナ文字の定義 |
hiragana |
ひらがな文字の定義 |
utf8_code |
日本語文字を含む文字コードを数バイト単位で定義したコード |
[[:alpha:]] |
V2.5で使用できる1バイトのアルファベット(大文字と小文字)の文字クラス式 |
[[:digit:]] |
V2.5で使用できる1バイトの数字の文字クラス式 |
. |
文字クラスではないが、上記と改行以外の1バイト文字 |
\n |
文字クラスではないが、改行文字 |
UTF-8コードについては、漢字や記号コードのすべてを列挙すると、それだけで膨大な量になりますので、簡易的な定義をしています。また、このようにすることで、よく利用する漢字や記号のすべてについてスキャンすることができます。
Windowsなどから、UTF-8コード以外で作られたテキストファイルをGEDITで読み込む場合には、注意が必要です。表面には現れませんが、FLEXで重要な働きをするバックスラッシュ(\マーク)コードが内部で化けるような現象も確認しています。 また、改行コードもWindowsからのファイルでは、GEDITで読み込んだときに「\r\n」となりますので、これを「\n」で置き換えることも必要のようです。簡単な例題などは、UTF-8に設定しておいて、文字はなるべくタイピングで入力することをお勧めします。
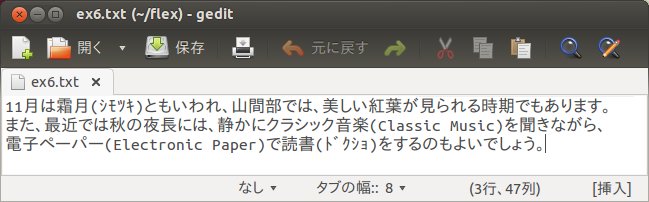
ここで、以下のようなテキストを作り、ex6.txtというファイルに保存します。
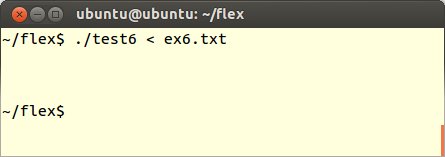
最初に定義したtest6.lexをコンパイル、実行してex6.txtを読み込ませます。そうすると改行だけが表示されます。
2番目にFLEXプログラムtest6.lexの規則部分を以下のように変更します。
%%
{katakana_1} { pr_text; }
[[:alpha:]] { }
[[:digit:]] { }
{katakana_2} { }
{hiragana} { }
{utf8_code} { }
. { }
\n {
pr_text; }
%%
これをコンパイル、実行して、ex6.txtを読み込ませます。すると1バイトカナカナ文字だけが表示されます。ここでpr_textというのは、パターンマッチした文字を表示させるためのマクロ名です。マクロの定義は#defineで定義してあります。
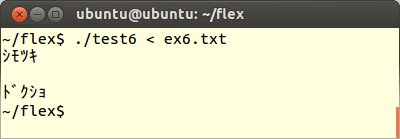
3番目にFLEXプログラムtest6.lexの規則部分を以下のように変更します。
%%
{katakana_1} { }
[[:alpha:]] { pr_text; }
[[:digit:]] { }
{katakana_2} { }
{hiragana} { }
{utf8_code} { }
. { }
\n {
pr_text; }
%%
これをコンパイル、実行してex6.txtを読み込ませます。すると1バイトのアルファベットだけが表示されます。
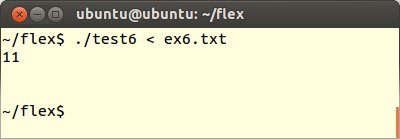
4番目にFLEXプログラムtest6.lexの規則部分を以下のように変更します。
%%
{katakana_1}
[[:alpha:]]
[[:digit:]] { pr_text; }
{katakana_2}
{hiragana}
{utf8_code}
.
\n {
pr_text; }
%%
これをコンパイル、実行してex6.txtを読み込ませます。すると1バイトの数字だけが表示されます。このとき規則部のパターンマッチ条件を記述して、それに対するアクション部分に{ }という空文を定義していたところが、今回はアクション部には何も記述していません。しかし、アクション部に何も書かないことと、{ }という空文を書くこととは結果的に同じであるといえます。
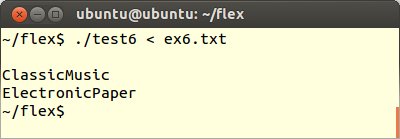
5番目にFLEXプログラムtest6.lexの規則部分を以下のように変更します。
%%
{katakana_1}
[[:alpha:]]
[[:digit:]]
{katakana_2} { pr_text; }
{hiragana}
{utf8_code}
.
\n {
pr_text; }
%%
これをコンパイル、実行してex6.txtを読み込ませます。する全角のカタカナ文字だけが表示されます。
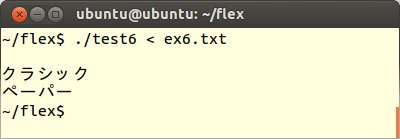
6番目にFLEXプログラムtest6.lexの規則部分を以下のように変更します。
%%
{katakana_1}
[[:alpha:]]
[[:digit:]]
{katakana_2}
{hiragana} { pr_text; }
{utf8_code}
.
\n {
pr_text; }
%%
これをコンパイル、実行してex6.txtを読み込ませます。するとひらがな文字だけが表示されます。
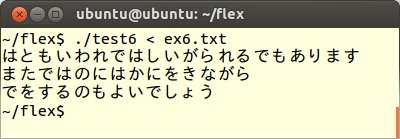
7番目にFLEXプログラムtest6.lexの規則部分を以下のように変更します。
%%
{katakana_1}
[[:alpha:]]
[[:digit:]]
{katakana_2}
{hiragana}
{utf8_code} { pr_text; }
.
\n {
pr_text; }
%%
これをコンパイル、実行してex6.txtを読み込ませます。すると漢字や句読点だけが表示されます。
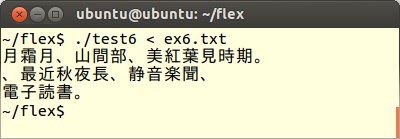
8番目にFLEXプログラムtest6.lexの規則部分を以下のように変更します。
%%
{katakana_1}
[[:alpha:]]
[[:digit:]]
{katakana_2}
{hiragana}
{utf8_code}
. { pr_text; }
\n {
pr_text; }
%%
これをコンパイル、実行してex6.txtを読み込ませます。するとこれまでに表示されていない1バイトの文字が表示されます。
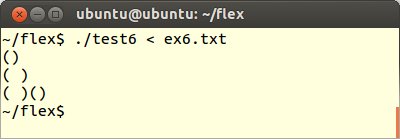
最後にFLEXプログラムtest6.lexの規則部分を以下のように変更します。
%%
{katakana_1} { pr_text; }
[[:alpha:]]
{ pr_text; }
[[:digit:]] { pr_text; }
{katakana_2} { pr_text; }
{hiragana} { pr_text; }
{utf8_code} { pr_text; }
. { pr_text; }
\n {
pr_text; }
%%
これをコンパイル、実行してex6.txtを読み込ませます。するとすべての文字が表示されます。

近年、日本語文書処理の中心はなんといっても日本語ワードプロセッサー(略してワープロ)ではないでしょうか。最近のワープロは専用の処理言語を搭載したものが珍しくないという状況になっているようです。
ワープロに標準で装備されていない機能でも、付属の処理言語を使えば機能を増やすことができるようになっているようです。しかし、それは一般の人々には非常に難解な部分でもあります。このときFLEXで日本語処理を行えば、かなり楽にできることもたくさんあるのではないでしょうか。
その一例として、送り仮名のチェックがあります。最近はパソコンに付属の標準日本語入力システムのみならず、さまざまな日本語入力システムが使用されています。そのため、かな漢字変換機能を利用すれば、送り仮名についてあまり意識せずに使うことができるようになっています。しかし、中には日本語入力システムでも、あいまいさを残した語句もあります。次のような文章を入力して、ex7.txtとします。
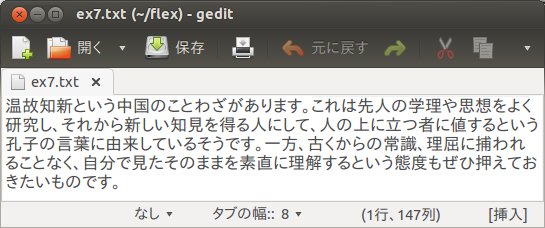
この文章では「押さえる」を「押える」という送り仮名を使っています。また、「捕らえる」を「捕える」という送り仮名を使っていますが、送り仮名の付け方として、誤読、難読がないようにという通則に従ってチェックをするプログラムをtest7.lexとします。
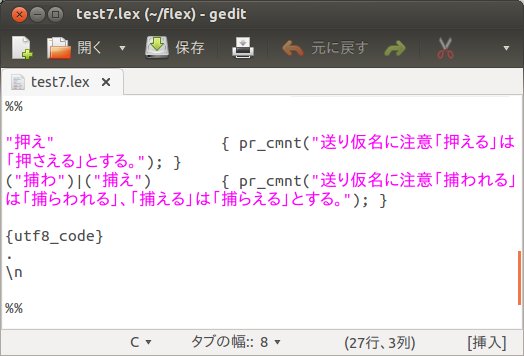
文字クラス定義部分については、test6.lexと同じ内容です。また、規則部分についても一行が長くなり過ぎたため、少し見づらいとは思いますが、メモ帳の表示画面を右端で折り返すモードで表示しています。さらにpr_cmntは文字列を表示させるマクロ定義です。
/* FLEX テストプログラム7
*/
%{
#include "flex_test.inc"
#define pr_cmnt(str) printf("%s\n",str)
%}
この文字クラス定義部はtest6.lexと同じ内容です。
int main()
{
yylex();
return(0);
}
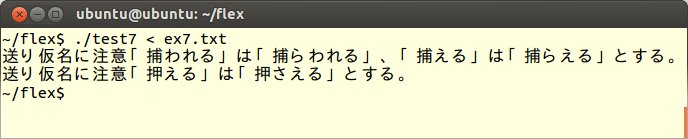
これをコンパイル、実行してex7.txtを読み込ませます。すると「押える」、「捕われる」についての注意事項が表示されます。このとき「捕われる」「捕える」を同じメッセージとして検出するために、パターンマッチ部の「捕わ」と「捕え」を「|」(バーティカル・バー)で結び、「または」という意味を持たせています。
次もFLEXプログラムで、文書チェッカーの機能を練習してみます。
日本語は同音異義語が大変多く存在する言語ではないでしょうか。この同音異義語は、かな漢字変換時には変換候補として表示されることもありますが、最終的には人間が選択し、決定をしなければなりません。うっかりすると用法をよく確かめずに、同音異義語の使い方を誤って使用してしまう場合もあるかもしれません。このようなことを防ぐためにも、文書を作成した後でチェッカーを利用して全体を校正することが考えられます。
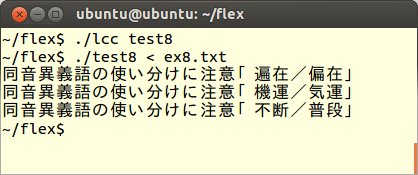
いま、次のような同音異義語の使い方が適切でない文書を作成し、これをex8.txtとして保存します。
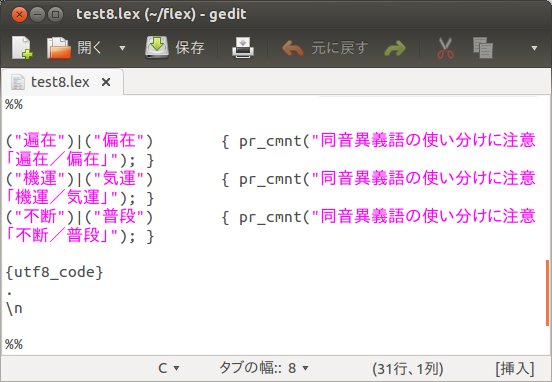
この文章では、「遍在」(どこにでも広くあるという意)を「偏在」(かたよっているという意)という言葉を使っています。また、「機運」(機会、時機がめぐるという意)を「気運」(歴史的背景の中での時流の意)という言葉を使っています。さらに「不断」(たゆまないという意)を「普段」(日常、平生の意)という言葉を使っています。これらをチェックをするFLEXプログラムをtest8.lexとします。
/* FLEX テストプログラム8
*/
%{
#include "flex_test.inc"
#define pr_cmnt(str) printf("%s\n",str)
%}
この文字クラス定義部はtest6.lexと同じ内容です。
int main()
{
yylex();
return(0);
}
これをコンパイル、実行してex8.txtを読み込ませます。すると同音異義語についての注意事項が表示されますので、文書作成者がこれに気付いて、あらためて注意箇所を校正することができます。
例えば、日本語ワープロで1ページ(40文字、36行)あたり1,440文字とすると、10ページで軽く1万文字を超えてしまいます。つまり一つの文書で数万文字を扱うというようなことは、日常的によくあることだと考えられます。この数万文字について、送り仮名や同音異義語をはじめ、表記についてもさまざまな規則や要求があると考えれらます。このような日本語文書を取り巻く状況で、大量の文書を素早く必要に応じてチェックをするために、FLEXで日本語文書処理を行うことは大変便利であると感じています。
Windows版では2バイト文字のうち、2バイト目が(16進数で)「5C」の文字には注意をする必要がありましたが、UbuntuでUTF-8コードを使う上ではそういった制約はありません。 この例題はWindwos版で2バイト目が「5C」の文字である「暴」を含む文書を作成しパターンマッチをするという確認を行いましたが、Ubuntu版では、特に漢字文字コードについて気にする必要はないのですが、Windwos版と同じようにやってみます。 このテキストをex9.txtとして保存します。
この文書において、「無暴」を「無謀」、「無謀」を「無暴」と自動的に変換するFLEXプログラムをtest9.lexとします。 ただし、二重引用符(ダブルクォーテーション)で囲まれた「無謀」という文字列については、変換しないというテクニックも使ってみます。
/* FLEX テストプログラム9 */
%{
#include "flex_test.inc"
#define pr_str printf("%s",yytext)
%}
%x string
%%
\" { pr_str;
BEGIN(string);}
<string>\" { pr_str; BEGIN(INITIAL);}
<string>. { pr_str; }
"無暴" { printf("無謀"); }
"無謀" { printf("無暴"); }
%%
int main()
{
yylex();
return(0);
}
これをコンパイル、実行してex9.txtを読み込ませます。 すると「無暴」を「無謀」と変換してくれますが、二重引用符(ダブルクォーテーション)で囲まれた「無謀」という文字列はそのまま残っていることが分かります。
ここで「%x string」という記述部分は、スタート状態というFLEXの機能を使っています。FLEXの文法について詳しいことは触れませんが、スタート状態によってある規則が活性化する条件をFLEXに通知するための論理値のようなものとされています。これによって二重引用符が認識されると<string>で始まる規則部分が適用されます。また、二度目の二重引用符が認識されると通常の規則処理に戻ります。

二重引用符の処理テクニックは日本語カスタマイザーでは、コメントの処理にも用いられています。ただし、C言語などは二重引用符の中でもさらに「\"」などが使われたりしますので、実際の日本語カスタマイザーではこれらのことにも対処できるようにしています。
文章を書くとき注意する事柄の一つに、表記の問題があると思います。日本語の中では、ある漢字複合語について別の読み方と区別するために、表記を分けて記述することがあります。 例えば名詞、形容動詞の「じょうず」を漢字で「上手」と書く場合がありますが、形容詞として「うまい」を「上手い」と同じ漢字を用いて表記する場合などです。これに対して、この二つの読み方を明確に分けるために、「上手い」という読み方に対しては、すべて「うまい」という平仮名で表記するという規則が求められる場合もあるかもしれません。 また、自分流の文書作成スタイルでは、特にこの二つを分けて書く習慣がない方もいらっしゃると思います。このようなときに、文書をすべて作成した後、一括して表記をチェックするという例についてFLEXプログラムで書いてみます。 次のような「上手」(じょうず)と「上手い」(うまい)を含む文章を作成し、ex10.txtとして保存します。
この文書において、「上手い」を「うまい」、「上手く」を「うまく」という表記上の注意を文章内に埋め込むFLEXプログラムをtest10.lexとします。ただし、「上手」(じょうず)という文字列については、何もしないというようにします。
/* FLEX テストプログラム10 */
%{
#include "flex_test.inc"
#define pr_str printf("%s",yytext)
%}
KEIYOSHI_1 "い"|"か"|"く"|"け"
%%
"上手"/{KEIYOSHI_1} { printf("[注意]上手→うま"); }
%%
int main()
{
yylex();
return(0);
}
「上手い」は「い」だけでなく、「上手かろう」「上手く」「上手ければ」などの活用が考えられますので、「上手」の後に続く数種類の平仮名を認識できることが必要となります。ここでは、文字クラスの中で数種類の平仮名を一括して定義しています。パターンマッチ部で用いる"/"(スラッシュ記号)は、先読み演算子として機能します。従って、「上手」に続く「い」「か」「く」「け」などがある限りパターンマッチしますが、そのときの「い」「か」「く」「け」は、まだマッチの対象とはなりません。
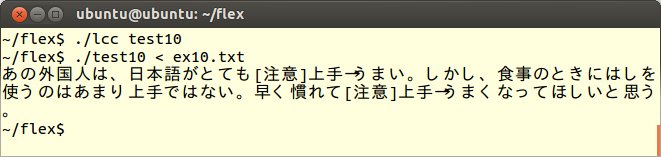
これをコンパイル、実行してex10.txtを読み込ませます。すると「上手い」や「上手く」について表記の注意はそこに記入されますが、「上手」(じょうず)の場合は何もしないことが分かります。
近年インターネット利用者数は、国内だけでも9,000万人を超えたといわれていますが、ネットサーフィンをするときには、気が付かないうちにCGI(コモン・ゲート・インターフェース)と呼ばれるプログラムが動作していることがあります。これは、ホームページなどを閲覧するブラウザーと呼ばれるソフトウェアが、インターネットサーバー上の情報を閲覧するだけではなく、ユーザーの方からサーバー側に情報を発信するときなどに、サーバー側の処理機能としてよく利用されています。
ubuntuというLinux/Unix系OS上では、apache2という定番のウェブサーバーソフトが用意されています。これも システム管理者であれば、インターネットから簡単にダウンロードすることができます。(apache2のバージョンはubuntu 13.10ではV2.4.6、ubuntu 14.04LTSではV2.4.7です) CGIはこのサーバーソフトと連動させるものです。最近は、Perlというスクリプト言語がCGIとして有名ですが、今回はこのCGIにFLEXを利用してみます。もともとC言語はCGIとして利用されることがありましたので、FLEXでもCGIは記述できるはずです。
(捕捉)ubuntu 14.04LTSでapache2のV2.4.7を使用する場合の注意点
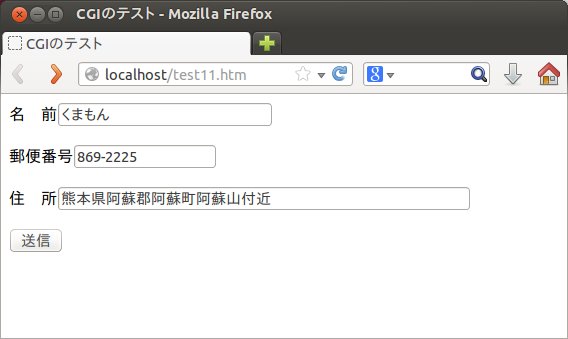
それではまず、テスト用のホームページtest11.htmをHTML言語で以下のように記述します。また、test11.htmは/var/www/フォルダー下に システム管理者権限でコピーしておきます。ここでは、formとinput要素を使って、氏名、郵便番号、住所が入力できるようにしました。送信ボタンをクリックすると、test11.cgiというプログラムが動作するようにします。
<html>
<head>
<meta http-equiv="content-type" content="text/html;charset=utf-8">
<title>CGIのテスト</title>
</head>
<body>
<form METHOD="POST" ACTION="http://localhost/cgi-bin/test11.cgi">
名 前<input TYPE="TEXT" NAME="NAME" size="18" ><br><br>
郵便番号<input TYPE="TEXT" NAME="ZIP" size="10"><br><br>
住 所<input TYPE="TEXT" NAME="ADDRESS" size="40"><br><br>
<input TYPE="submit" VALUE="送信">
</body>
</html>
test11.cgiを作るために、FLEXでtest11.lexというプログラムを以下のように記述しておきます。ここでは、inputで指定したNAMEに対応して、文字列を表示するという簡単なものです。また、「&」文字を受け取ると、ブラウザー上で改行するようにしています。
/* FLEX テストプログラム11 */
%{
#include "flex_test1.inc"
%}
%%
NAME= { pr_text; }
ZIP= { pr_text; }
ADDRESS= { pr_text; }
& { printf("<br>"); }
%%
int main()
{
pr_web_out1;
yylex();
pr_web_out2;
return(0);
}
また、flex_test1.incの内容は以下のようになります。POSTメソッドの場合には、最初に"CONTENT_LENGTH"という環境変数によって、文字列全体の長さをチェックすることが義務付けられていますので、その部分の最大長さを10,000バイトとしています。
#define YY_SKIP_YYWRAP
int yywrap( void ) { return(1); }
#define pr_text printf("%s",yytext)
#define MAX_DATA_SIZE 10000
#define check_size
if((int)getenv("CONTENT_LENGTH") > MAX_SIZE ) exit(1)
#define pr_web_out1 check_size;\
printf("content-type: text/html\n");\
printf("\n");\
printf("<!DOCTYPE HTML PUBLIC \"-//W3C//DTD HTML 4.01 Transitional//EN\">\n");\
printf("<html lang=\"ja\">\n");\
printf("<head>\n");\
printf("<meta http-equiv=\"Content-Language\" content=\"ja\">\n");\
printf("<meta http-equiv=\"content-type\" content=\"text/html;charset=utf-8\">\n");\
printf("<body>\n")
#define pr_web_out2 printf("</body></html>\n")
test11.lexをflexとgccでコンパイルした後、実行可能ファイル名をtest11.cgiに変更し、ubuntuの場合には、/usr/lib/cgi-bin/というフォルダーの下にシステム管理者権限でコピーしておきます。
ここで、apacheサーバーが動いているときには、http://localhost/test11.htmをブラウザーで表示させると以下のようになりますので、実際に名前、郵便番号、住所の項目に入力して、送信ボタンをクリックします。
すると、以下のようにNAME(名前)、ZIP(郵便番号)、ADRESS(住所)に対応した文字列を受け取って表示します。また、HTML言語のform要素において、POSTメソッドを指定した場合には、標準入力で文字列が受け渡されます。ただし、日本語の文字列は%に続く数字によって表されています。
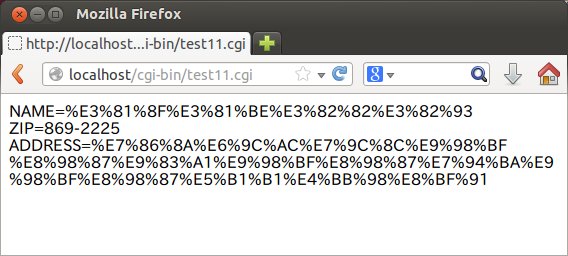
このようにapacheサーバー上では、FLEXプログラムがCGIとして動作することが分かりました。
次に、apacheサーバーが動作しているubuntuマシンに、ローカルエリアで接続されているWindowsパソコンからアクセスして、CGI動作を確認してみます。また、今回はCGIに渡された文字列を正しい日本語に変換するということもやってみたいと思います。
まず、テスト用のホームページtest12.htmをHTML言語で以下のように記述し、test12.htmとして システム管理者権限で/var/www/フォルダー下にコピーしておきます。送信ボタンをクリックすると、test12.cgiというプログラムが動作するようにします。
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML
4.01 Transitional//EN">
<html>
<head>
<meta http-equiv="content-type" content="text/html;charset=utf-8">
<title>CGIのテスト</title>
</head>
<body>
<form METHOD="POST" ACTION="/cgi-bin/test12.cgi">
名 前<input TYPE="TEXT" NAME="NAME" size="18" ><br><br>
郵便番号<input TYPE="TEXT" NAME="ZIP" size="10"><br><br>
住 所<input TYPE="TEXT" NAME="ADDRESS" size="40"><br><br>
<input TYPE="submit" VALUE="送信">
</body>
</html>
test12.cgiは、FLEXでtest12.lexというプログラムにより記述します。ここでは、前回のtest11.lexに加えて文字列を変換する機能を付けています。一応UTF-8で 連続した3バイト分のコードパターンだけを文字に変換することはやっていますが、あくまでも簡単なテスト的なものです。また、郵便番号は赤文字で表示させるようにしてみます。(flex_test1.incは前回と同じものです)
/* FLEX テストプログラム12 */
%{
#include <string.h>
#include "flex_test1.inc"
#define ch_code(ch1,ch2) ( ( ch1 & 0x40 ? ch1 - 0x37 : ch1 - 0x30 ) <<
4 ) +\
( ch2 & 0x40 ? ch2 - 0x37 : ch2 - 0x30 )
%}
zip_type [0-9]+-[0-9]+
other_char .
%%
NAME= { pr_text; }
ZIP= { pr_text; }
ADDRESS= { pr_text; }
& { printf("<br>"); }
{zip_type} { printf("<font color=\"red\">%s</font>",yytext); }
(%..)(%..)(%..) { printf("%c%c%c",
ch_code(yytext[1],yytext[2]),
ch_code(yytext[4],yytext[5]),
ch_code(yytext[7],yytext[8])); }
{other_char}
%%
int main()
{
pr_web_out1;
yylex();
pr_web_out2;
return(0);
}
test12.lexをflexとgccでコンパイルした後、実行可能ファイル名をtest12.cgiに変更しシステム管理者権限で/usr/lib/cgi-bin/フォルダーの下にコピーしておきます。
ここで、ローカルエリアに接続されているWindowsパソコン上からは、ubuntuのローカルアドレス(プライベートIPアドレス)が192.168.3.Xとして見えることを確認して、http://192.168.3.X/test12.htmをブラウザーで表示させます。(Xは接続しているルーターによって決められている範囲内の数字です)
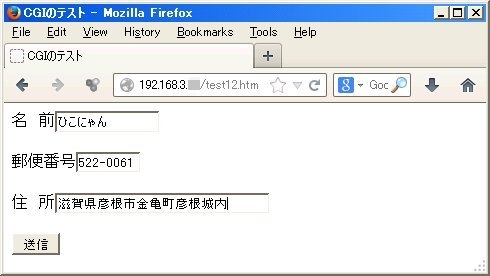
実際に名前、郵便番号、住所の項目に入力して、送信ボタンをクリックします。
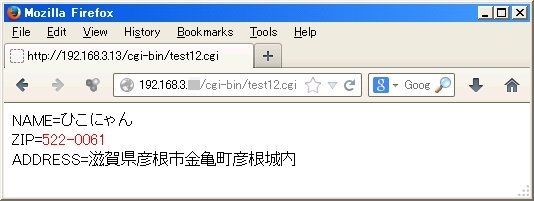
前回と違い、今度は日本語に変換されて表示されました。
これまではHTML言語のform要素で、POSTメソッドを使用して文字列のやり取りを行いましたが、form要素にはGETメソッドという方法により、文字列のやり取りもできるようになっています。POSTメソッドの場合には、標準入力が文字列のやり取りに使われているため、FLEX側では特に何も気にせずに字句解析できましたが、GETメソッドを使用する場合にはFLEXプログラム側もひと工夫する必要があるようです。GETメソッドでは環境変数の「QUERY_STRING」というものが使用されます。
GETメソッドテスト用のホームページtest12-G.htmをHTML言語で以下のように記述し、test12-G.htmとして/var/www/フォルダー下にコピーしておきます。送信ボタンをクリックすると、test12-G.cgiというプログラムが動作するようにします。
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<meta http-equiv="content-type" content="text/html;charset=utf-8">
<title>CGIのテスト</title>
</head>
<body>
<form METHOD="GET" ACTION="/cgi-bin/test12-G.cgi">
名 前<input TYPE="TEXT" NAME="NAME" size="18" ><br><br>
郵便番号<input TYPE="TEXT" NAME="ZIP" size="10"><br><br>
住 所<input TYPE="TEXT" NAME="ADDRESS" size="40"><br><br>
<input TYPE="submit" VALUE="送信">
</body>
</html>
test12-G.cgiは、test12-G.lexというプログラムにより記述します。ここでは、環境変数の「QUERY_STRING」をシェルコマンドの「printenv」で表示させる機能がありますが、これをC言語のpopenというパイプ機能を使ってFLEXのyyinで読めるようにしています。また、「YY_NEW_FILE」により、yyinが新しいファイルを指すようにしています。
/* FLEX テストプログラム12-G */
%{
#include <string.h>
#include <stdlib.h>
#include "flex_test2.inc"
#define ch_code(ch1,ch2) ( ( ch1 & 0x40 ? ch1 - 0x37 : ch1 - 0x30 ) <<
4 ) +\
( ch2 & 0x40 ? ch2 - 0x37 : ch2 - 0x30 )
%}
zip_type [0-9]+-[0-9]+
other_char .
%%
NAME= { pr_text; }
ZIP= { pr_text; }
ADDRESS= { pr_text; }
& { printf("<br>"); }
{zip_type} { printf("<font color=\"red\">%s</font>",yytext); }
(%..)(%..)(%..) { printf("%c%c%c",
ch_code(yytext[1],yytext[2]),
ch_code(yytext[4],yytext[5]),
ch_code(yytext[7],yytext[8])); }
{other_char}
%%
int main()
{
pr_web_out1;
yyin = popen( "printenv QUERY_STRING","r" );
YY_NEW_FILE;
yylex();
pclose(yyin);
pr_web_out2;
return(0);
}
また、flex_test2.incの内容は以下のようになります。
#define YY_SKIP_YYWRAP
int yywrap( void ) { return(1); }
#define pr_text printf("%s",yytext)
#define pr_web_out1 printf("content-type: text/html\n");\
printf("\n");\
printf("<!DOCTYPE HTML PUBLIC \"-//W3C//DTD HTML 4.01 Transitional//EN\">\n");\
printf("<html lang=\"ja\">\n");\
printf("<head>\n");\
printf("<meta http-equiv=\"Content-Language\" content=\"ja\">\n");\
printf("<meta http-equiv=\"content-type\" content=\"text/html;charset=utf-8\">\n");\
printf("<body>\n")
#define pr_web_out2 printf("</body></html>\n")
ここで、http://192.168.3.X/test12-G.htmを無線LAN(wi-fi)接続しているAndroid端末で表示させます。(Xは接続しているルーターによって決められている範囲内の数字です)
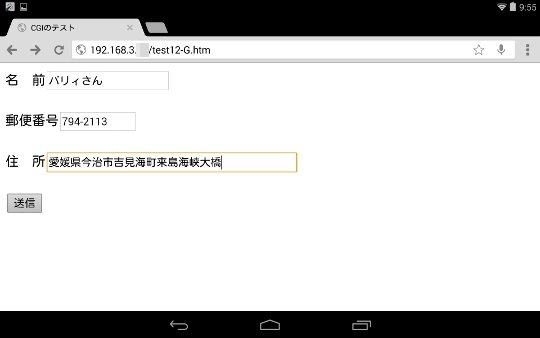
実際に名前、郵便番号、住所の項目に入力して、送信ボタンをクリックします。
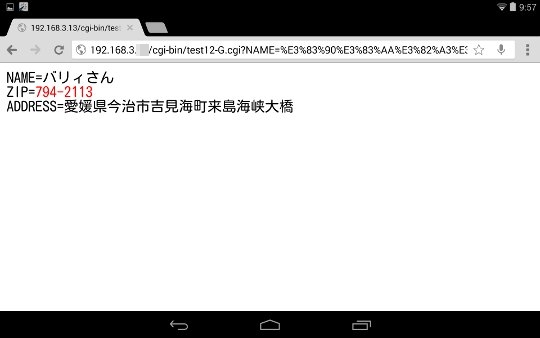
このようにGETメソッドでも、FLEXプログラムのCGIは、うまく動作することを確認しました。今回は簡単のためにローカルアドレスをそのまま使用しましたが、ubuntuでは/etc/hostsをはじめ、他の設定ファイルを編集することにより、ドメインネームが使用できます。また、Windwosでも同様にhostsファイルを編集することで、ローカルアドレスをドメインネームとして使うことができます。(説明が長くなりますので、ここでは割愛させていただきます)
さらに、apacheサーバーを外部に公開し、グローバルIPアドレス(WAN側)から参照するときには、ルーターのDHCP設定や静的IPマスカレード設定などを適切に行えば、グローバルIPアドレスでホームページ参照や、CGIの実行ができるようになります。
これまで種々のFLEXを利用した文字処理の練習問題を提示してきましたが、これらの基本的なテクニックを使用して、日本語カスタマイザーのヒントともいうべき練習をやってみます。
次のようなテキストファイルex13.txtを準備します。このテキストには、各行の先頭に「#日本語定義」という文字列があります。その後に区切り文字(空白、タブ)をはさんで日本語の文字列が入力されています。
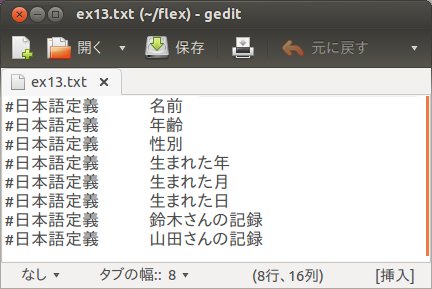
このテキストファイルをFLEXプログラムから読み込むと、FLEXの規則部分を出力するようにします。
/* FLEX テストプログラム13 */
%{
#include "flex_test.inc"
int auto_num = 0;
#define pr_text printf("%s",yytext)
#define pr_dq_text printf("\"%s\"",yytext)
#define pr_autonum printf(" { printf(\"jp_str_%-d\"); }\n",auto_num);++auto_num
#define pr_rule printf("%%%%\n")
%}
この文字クラス定義部はtest6.lexと同じ内容です。
%x JP_DEF
%x JP_STRING
%%
^"#日本語定義" { BEGIN(JP_DEF); }
<JP_DEF>[ \t]+ { BEGIN(JP_STRING); }
<JP_STRING>{utf8_code} { pr_dq_text; }
<JP_STRING>\n { pr_autonum; BEGIN(INITIAL); }
.
\n
%%
int main()
{
pr_rule;
yylex();
pr_rule;
return(0);
}
このFLEXプログラムでは、あらかじめ「JP_DEF」状態と「JP_STRING」状態の二つの状態を持っています。まず、テキスト各行の先頭で「#日本語定義」という文字列を見つけると、「JP_DEF状態」に遷移します。
そして、区切り文字(空白、タブ)が一つ以上あれば、さらに「JP_STRING状態」に遷移します。そして、日本語文字列を認識するたびにダブルクォートで囲んで出力するという処理を行っています。さらに、改行を認識すると初期状態に戻ります。ubuntu6.10の処理系では、区切り文字を文字クラスで定義していましたが、ubuntu13.10の処理系ではうまく動いてくれないようです。そこで、直接規則の部分に区切り文字の定義をしています。 こういうところが、やはりプログラミングは実際にコードを書いて動かしてみないと分からないものだとつくづく思いました。
このプログラムを実行した結果を以下に示します。
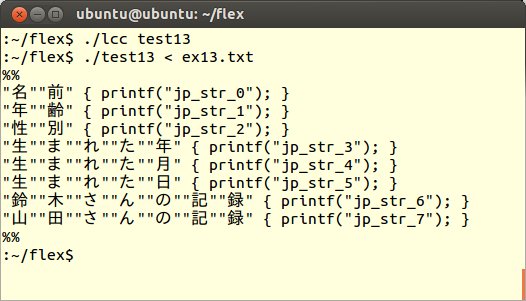
このプログラムは、規則の部分を非常にシンプルに書いていますが、実際の日本語カスタマイザーは、もう少し複雑な処理を行っていて、日本語文字列の間に半角英数記号が入っていたときや、コメント処理などのさまざまな文字列の場合に、柔軟な対応ができるようにしてあります。
この例題プログラムでは、日本語文字一文字をそれぞれダブルクォートで囲んでいますが、このような書き方をしても、FLEX処理系は問題なく処理してくれるようです。また、jp_strという文字列に続く自動番号は、マクロ定義によってシンプルに実現しています。さらに、FLEXの規則部分に使用される「%%」記号は、main()において、yylex()による字句解析の前と後でそれぞれ出力しています。
また、この例題だけを考えると、何も状態を二つも持つ必要はありませんが、あとで機能を拡張することを考えると、二つある方が良いのではないでしょうか。簡単な例題ではありますが、日本語カスタマイザー作成の十分なヒントになると考えています。
今回は、例題FU-5の続編として、もう少し日本語で書いたC言語風プログラムを処理するための練習をやってみたいと思います。このFLEXの記述は、日本語カスタマイザーの2パス目の処理を行うためのヒントになると考えています。
まず、次のようなテキストファイルex14.txtを準備します。ex14.txtファイルを作成して、以下のように入力、保存しておきます。このテキストは、例題FU-5で使用したテキストの先頭部分に、日本語定義の宣言が付加されたものです。
/* 個人情報を印字する */
#include <stdio.h>
#日本語定義 型なし "void"
#日本語定義 整数型 "int"
#日本語定義 文字型 "char"
#日本語定義 はじまり "main"
#日本語定義 通常終了 "return(0)"
#日本語定義 印字 "printf"
#日本語定義 構造体 "struct"
#日本語定義 個人情報型 "person"
#日本語定義 名前
#日本語定義 年齢
#日本語定義 性別
#日本語定義 生まれた年
#日本語定義 生まれた月
#日本語定義 生まれた日
#日本語定義 鈴木さんの記録
#日本語定義 山田さんの記録
構造体 個人情報型 {
文字型 名前[30];
整数型 年齢;
文字型 性別[4];
整数型 生まれた年;
整数型 生まれた月;
整数型 生まれた日;
};
整数型 はじまり(型なし)
{
構造体 個人情報型 鈴木さんの記録 = {"鈴木太郎",46,"男",1963,2,14};
構造体 個人情報型 山田さんの記録 = {"山田花子",35,"男",1974,8,23};
印字("名前=%s\n",鈴木さんの記録.名前);
印字("年齢=%d歳\n",鈴木さんの記録.年齢);
印字("性別=%s\n",鈴木さんの記録.性別);
印字("生年月日=%d年",鈴木さんの記録.生まれた年);
印字("%d月",鈴木さんの記録.生まれた月);
印字("%d日生まれ\n\n",鈴木さんの記録.生まれた日);
印字("名前=%s\n",山田さんの記録.名前);
印字("年齢=%d歳\n",山田さんの記録.年齢);
印字("性別=%s\n",山田さんの記録.性別);
印字("生年月日=%d年",山田さんの記録.生まれた年);
印字("%d月",山田さんの記録.生まれた月);
印字("%d日生まれ\n",山田さんの記録.生まれた日);
通常終了;
}
例題FU-5と違うところは、「#日本語定義」という文字列から始まる一行文は、そのまま何も処理しないで、スキップさせています。これは状態遷移を利用しています。さらに、例題FU-5でも少し触れましたが、C言語の文字列中は、FLEXの置き替え規則を適用しないようにしています。これも状態遷移を利用しています。このFLEXプログラムを以下に示します。
/* FLEX テストプログラム14 */
%{
#include "flex_test.inc"
#define pr_text printf("%s",yytext)
%}
%x SKIP
%x STRING
%%
^"#日本語定義" { BEGIN(SKIP);}
<SKIP>\n { BEGIN(INITIAL);}
<SKIP>. { }
\" { pr_text; BEGIN(STRING);}
<STRING>\" { pr_text; BEGIN(INITIAL);}
<STRING>. { pr_text; }
"型なし" { printf("void"); }
"整数型" { printf("int"); }
"文字型" { printf("char"); }
"はじまり" { printf("main"); }
"通常終了" { printf("return(0)"); }
"印字" { printf("printf"); }
"構造体" { printf("struct"); }
"個人情報型" { printf("person"); }
"名前" { printf("jp_str_1"); }
"年齢" { printf("jp_str_2"); }
"性別" { printf("jp_str_3"); }
"生まれた年" { printf("jp_str_4"); }
"生まれた月" { printf("jp_str_5"); }
"生まれた日" { printf("jp_str_6"); }
"鈴木さんの記録" { printf("jp_str_7"); }
"山田さんの記録" { printf("jp_str_8"); }
%%
int main()
{
yylex();
return(0);
}
このtest14.lexをコンパイルし、ex14.txtを読み込むと次のような結果が出力されます。
/* 個人情報をprintfする */
#include <stdio.h>
struct person {
char jp_str_1[30];
int jp_str_2;
char jp_str_3[4];
int jp_str_4;
int jp_str_5;
int jp_str_6;
};
int main(void)
{
struct person jp_str_7 = {"鈴木太郎",46,"男",1963,2,14};
struct person jp_str_8 = {"山田花子",35,"男",1974,8,23};
printf("名前=%s\n",jp_str_7.jp_str_1);
printf("年齢=%d歳\n",jp_str_7.jp_str_2);
printf("性別=%s\n",jp_str_7.jp_str_3);
printf("生年月日=%d年",jp_str_7.jp_str_4);
printf("%d月",jp_str_7.jp_str_5);
printf("%d日生まれ\n\n",jp_str_7.jp_str_6);
printf("名前=%s\n",jp_str_8.jp_str_1);
printf("年齢=%d歳\n",jp_str_8.jp_str_2);
printf("性別=%s\n",jp_str_8.jp_str_3);
printf("生年月日=%d年",jp_str_8.jp_str_4);
printf("%d月",jp_str_8.jp_str_5);
printf("%d日生まれ\n",jp_str_8.jp_str_6);
return(0);
}
この結果をexout.cというファイルに保存し、コンパイルして実行結果を確認します。
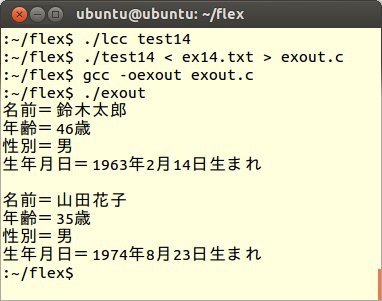
例題FU-5の結果とは違い、二重引用符(ダブルクォーテーション)で囲まれた文字列は変換されないことが分かります。この例はシンプルな文字列に対応して処理していますが、実際のC言語では、文字列中の中で、さらに二重引用符が使われることもあります。一方、C言語用の日本語カスタマイザーでは、このことにも対応しています。今回は、「/*」「*/」のコメント処理について触れてはいませんが、大体この二重引用符と同じような規則の書き方になります。
また、「#日本語定義」という文字列から始まる一行文は、完全に読み飛ばし(無視)されていることも分かります。この点について、C言語用の日本語カスタマイザーでは、この行の最後にコメントが入っている場合であっても、コメント部分だけは出力するようにしてあります。以上のことから、日本語カスタマイザーの2パス目では、変換規則と共に、これらの処理ができるようにしておくことが必要となります。
今回は、日本語処理というよりも、FLEXを使って自動販売機のシミュレーションをやってみたいと思います。最近、自動販売機はおサイフケータイでも使えるようになっているみたいですが、全国的には、まだまだお札やコインで商品を購入することが一般的なようです。
普通、自動販売機の動作を考えるときには、まず状態遷移図で設計することが多いと思いますが、自分で書いてみると、かなり複雑な図になってしまいます。そこで、FLEXで直接その動作を記述できないかと考え、やってみたところ意外とすっきり書けることが分かりました。
今回の自動販売機としては、商品は「商品A」、「商品B」、「商品C」の3種類だけで、価格はそれぞれ100円、120円、150円とします。この自動販売内に投入できるお金は、1000円札、500円コイン、100円コイン、50円コイン、10円コインだけとします。1円コイン、5円コインなどは受け付けられずに、自動的にコイン返却口に戻るものとします。 また、2000円札、5000円札、10000円札も同様に紙幣判別機では受け付けられずに、入れても自動的に返却されるものとします。
さらに、1000円札、500円コイン、100円コイン、50円コイン、10円コインについては、それぞれ許容上限が決まっていて、1000円札は1枚、500円コインは3枚、100円コインは4枚、50円コインは18枚、10円コインは40枚までしか受け付けないこととし、上限を超えた紙幣やコインは自動的に返却されるものとします。この制限も今回のプログラムでチェックするようにしています。
こられのシミュレーションを行なうFLEXプログラムをtest15.lexとして、以下に示します。
/* FLEX テストプログラム15 */
%{
#include "flex_test.inc"
void ad_money( int ),out_shouhin( int );
int yen_10,yen_50,yen_100,yen_500,yen_1000,goukei = 0;
#define pr_money printf("%sが投入されました。",yytext)
#define pr_goukei printf(" 合計は%d円\n",goukei)
#define henkyaku printf("お金は返却されました\n")
#define reset yen_10, yen_50, yen_100, yen_500, yen_1000, goukei=0
#define LIMIT_10 40
#define LIMIT_50 18
#define LIMIT_100 4
#define LIMIT_500 3
#define LIMIT_1000 1
%}
%%
10円 { ad_money(10); }
50円 { ad_money(50); }
100円 { ad_money(100); }
500円 { ad_money(500); }
1000円 { ad_money(1000); }
商品A { out_shouhin(100); pr_goukei; if( goukei==0 ) reset; }
商品B { out_shouhin(120); pr_goukei; if( goukei==0 ) reset; }
商品C { out_shouhin(150); pr_goukei; if( goukei==0 ) reset; }
返却 { printf("おつりを%d円返却しました。\n\n",goukei); reset; }
\n {}
. {}
%%
void ad_money( int yen) {
switch (yen) {
case 10: if (yen_10 < LIMIT_10)
{ ++yen_10; goukei+=yen; pr_money; pr_goukei;}
else henkyaku; break;
case 50: if (yen_50 < LIMIT_50)
{ ++yen_50; goukei+=yen; pr_money; pr_goukei; }
else henkyaku; break;
case 100: if (yen_100 < LIMIT_100)
{ ++yen_100; goukei+=yen; pr_money; pr_goukei; }
else henkyaku; break;
case 500: if (yen_500 < LIMIT_500)
{ ++yen_500; goukei+=yen; pr_money; pr_goukei; }
else henkyaku; break;
case 1000: if (yen_1000 < LIMIT_1000)
{ ++yen_1000; goukei+=yen; pr_money; pr_goukei; }
}
}
void out_shouhin( int yen) {
if ( goukei - yen >=0 ) {
goukei-=yen;
printf("%d円の商品を出しました。",yen);
}
else
printf("残高が足りません。");
}
int main()
{
yylex();
return(0);
}
次に、入力用のファイルex15.txtを用意します。このとき、入れた紙幣やコインは、「1000円」、「500円」、「100円」、「50円」、「10円」として入力します。また、商品選択ボタンが押された場合として、それぞれ「商品A」、「商品B」、「商品C」を入力します。最後に、返却レバーが回されることに対応して、「返却」を入力します。
FLEXプログラムtest15.lexをコンパイルし、このex15.txtを読み込むと次のような結果が出力されます。
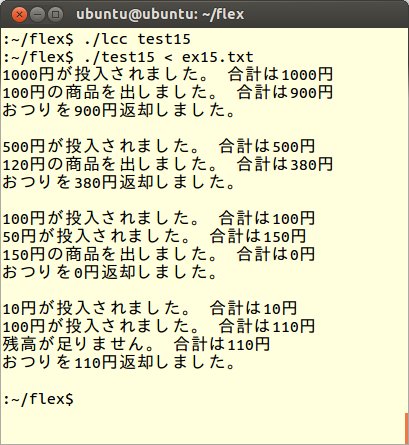
いろいろと入力を変えてみて、動作を観察するのも面白いと思います。
このサイトでは日本語カスタマイザーを利用して、プログラム言語の中で何とかして日本語を記述できるようにしようという試行の記録を掲載してきました。
試作当初は学会発表のレジュメで記述した日本語カスタマイザーの内容から、さまざまな試行実験を行うちにFLEXプログラムも少しずつ変わってきました。これからも変わっていくことは予想されますが、ここで簡単に「#日本語定義」部分について解説してみたいと思います。
プログラム言語の中で記述する日本語定義部分は、必ず行の先頭で「#日本語定義」から始まる文字列によって指定します。その後に1文字以上の区切り文字に続き、UTF-8において考えられる日本語の全角文字集合から始まる文字列とします。このとき、二文字目以降には英数文字でも構いませんが、最初の一文字は必ず日本語文字でなければならないこととします。この部分までだけならばこの日本語文字列(英数文字混在も可)は、自動的に変数が割り当てられます。
次に日本語文字列から、さらに区切り文字に続いて「"」(半角ダブルクォーテーションマーク)で囲った英数記号文字列を記述すると、日本語文字列をその英数記号文字列で置き換えることとします。この半角英数記号文字とは、半角英数文字に加えて、各種記号も認識できるようにしますが、これはプログラム言語で使われる予約語やコメント記号などとの兼ね合いによって、決められるものと考えています。以下にこの部分の状態遷移図を示します。
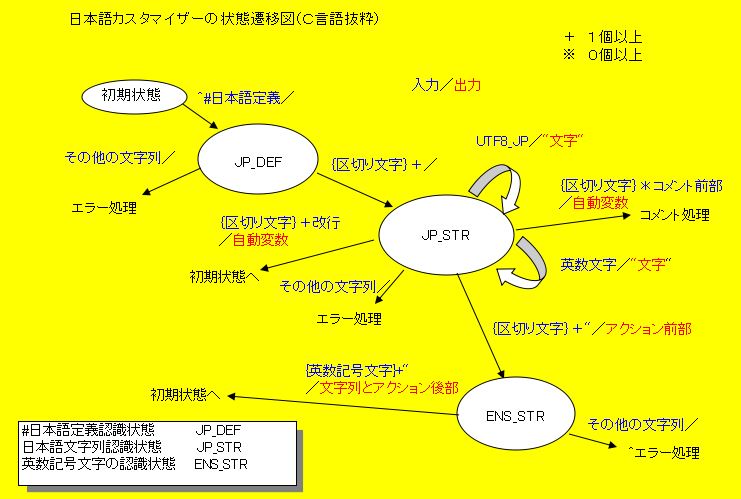
ここで、区切り文字というのは空白やタブのことです。これはC言語用の状態遷移図で、C言語のコメントは/*と*/で囲まれた部分ですので、コメント前部は/*を意味します。
一方、Java言語のコメントは/*から*/までと、//以降改行までの二種類がありますが、このJava言語用日本語FLEXプログラムを以下に示してみます。
/* 日本語カスタマイザー Java */
§定義や前処理部のはじまり
#include "jjava_rule.inc"
§定義や前処理部の終わり
全角UTF8文字集合 (\xc2).|(\xC3).|(\xC4).|(\xC5).|(\xc6).|(\xc7).|(\xc8).|(\xc9).|(\xcA).|(\xcB).|(\xcc).|(\xcd).|(\xce).|(\xcf).|(\xd0).|(\xd1).|(\xd2).|(\xd3).|(\xd4).|(\xd5).|(\xd6).|(\xd7).|(\xd8).|(\xd9).|(\xdA).|(\xdb).|(\xdc).|(\xde).|(\xdf).|(\xe2)..|(\xe3)..|(\xe4)..|(\xe5)..|(\xe6)..|(\xe7)..|(\xe8)..|(\xe9)..|(\xef)..
英数記号文字集合 [[:alpha:][:digit:]_{}()., ~!#@$%^&+*-=:;/|<>']|"["|"]"|[\\\\]|[\\\"]
区切り文字集合 [ \t]
二重引用符 \"
§排他的開始 注釈*
§排他的開始 注釈//
§排他的開始 日本語定義
§排他的開始 日本語文字列
§排他的開始 英数記号文字列
§規則のはじまり
"/*" { 状態遷移→(注釈*); }
<注釈*>"*/" { 状態遷移→(初期状態); }
<注釈*>ほかの文字
"//" { 状態遷移→(注釈//); }
<注釈//>\n { 状態遷移→(初期状態); }
<注釈//>ほかの文字
行頭|"#日本語定義" { 状態遷移→(日本語定義); }
<日本語定義>{区切り文字集合}+ { 状態遷移→(日本語文字列); }
<日本語定義>{区切り文字集合}+{英数記号文字集合} { エラー処理; }
<日本語定義>ほかの文字 { エラー処理; }
<日本語文字列>{全角UTF8文字集合} { 文字列の出力; }
<日本語文字列>[[数字集合][英文字集合]]+ { 文字列の出力; }
<日本語文字列>{区切り文字集合}*改行 { 番号の付いた識別子を生成; 状態遷移→(初期状態); }
<日本語文字列>{区切り文字集合}*"//" { 番号の付いた識別子を生成; 状態遷移→(注釈//); }
<日本語文字列>{区切り文字集合}*"/*" { 番号の付いた識別子を生成; 状態遷移→(注釈*); }
<日本語文字列>{区切り文字集合}*{二重引用符} { 文字出力の定義前部; 状態遷移→(英数記号文字列); }
<日本語文字列>ほかの文字 { エラー処理; }
<英数記号文字列>{英数記号文字集合}+{二重引用符} { 文字出力の文字部; 文字出力の定義後部; 状態遷移→(初期状態);}
<英数記号文字列>ほかの文字 { エラー処理; }
ほかの文字 { 出力停止; }
改行 { 出力停止; }
ファイルの終わり { 解析を強制終了; }
§規則の終わり
整数型 はじまり(型なし)
{
ファイル2への出力前半部;
字句解析部;
ファイル2への出力後半部;
解析終了;
}
Javaの日本語カスタマイザープログラムは、これ自身も日本語で書いています。日本語定義部分と「jjava_rule.inc」は掲載していませんが、FLEXプログラムは以外とすっきり書けるのではないかという気がします。 言うまでもありませんが、これが決定版のJava用日本語カスタマイザーというわけてはなく、このサイトの演習ぐらいはできるというぐらいですので、改良のため変更することも度々あると思いますが、 これからプログラム言語の日本語化をやってみたいという方々の一助となれば幸いです。
yywrap関数の返す値は、構文解析器であるbisonと字句解析器であるflexとのインターフェースとして使われているようです。両者のインターフェースでは、トークンと呼ばれる数値により、やり取りが行なわれています。このサイトでは、主にflexを単体で使用することがほとんどですからyywrap関数の値を1(通常値)にしておけば、特にこの関数について気にする必要はないと考えています。
ここで、もし日本語カスタマイザーの前半処理部分をflexではなく、bisonで書き直せばどうなるのでしょうか。確かに「#日本語定義」部分だけはflexで書くよりもすっきりと記述できそうです。しかし、bisonで書こうとすると、「#日本語定義」部分以外をどうするかが問題となります。もし、各プログラム言語で規定されているすべての構文規則について記述するとなると、エラーの出ないように記述しないと、パーサーエラーメッセージが続出してしまいます。これではまず実現がとても難しいと思います。また、「#日本語定義」部以外はflexの方で処理しないようにするという方法も考えられますが、flexとbison間の文字列をやり取りするインターフェースを考える必要があります。やはり日本語カスタマイザーについては、flexの字句解析を2回行う方が、より簡単に実現できるのではないでしょうか。


参考図書
オートマトン・言語理論 本多波雄著 コロナ社 1972
UNIXプログラミング環境 Brian W.Kernighan Rob Pike 石田晴久監訳 アスキー出版局 1985
プログラミング言語C B.W. カーニハン D.M. リッチー 石田晴久訳 共立出版社 1981
UNIX 石田晴久著 共立出版社 1983
情報通信プロトコル 秋丸春夫 奥山徹共著 オーム社 2001
yacc/lex 五川女健治著 啓学出版社 1992
flex, version2.5 A Fast Scannar Generator ドキュメント University of California. Vern Paxsonほか多数のAuthor編著
Cプリプロセッサー・パワー 林晴比古著 日本ソフトバンク出版社 1988
HTMLハンドブック 渡辺竜生著 ソフトバンクパブリッシング 1999
ubuntu6.10 システム utf-8 manual page
RFC3875 The Common Gateway Interface CGI Version 1.1