
TUT-CODE定義ファイル
2010年11月30日に常用漢字 (1945文字)から5文字削除されて、196文字が追加されましたので、新常用漢字は2,136文字と正式発表されています。この結果、従来のTUT-CODEでは新常用漢字全体を網羅することができなくなりました。 また、これに伴い、新聞協会、共同通信、朝日新聞、NHKなどは、新常用漢字以外にも独自に使用する漢字を発表しております。そこで、新常用漢字にあってもTUT-CODEにはない52文字 +各社が独自に使用を決めた漢字11文字=63文字を拡張コードとして追加割り付けしてみました。
| 漢字 | コード | 漢字 | コード | 漢字 | コード | 漢字 | コード | 漢字 | コード | 漢字 | コード |
| 拉 | dgg | 鵜 | wgg | 踪 | phh | 刹 | qtt | 疹 | dvv | 彙 | jnn |
| 顎 | khh | 嘲 | fgg | 蔽 | qgg | 遜 | .hh | 扮 | kmm | 沃 | evv |
| 鬱 | egg | 爽 | jhh | 慄 | cgg | 杭 | xgg | 哨 | lnn | 憬 | imm |
| 捉 | ihh | 捧 | agg | 傲 | ,hh | 挽 | ctt | 賂 | sbb | 捗 | abb |
| 妬 | lhh | 挫 | ;hh | 捻 | ftt | 箋 | ,yy | 氾 | /yy | 訃 | ;nn |
| 昧 | sgg | 丼 | lyy | 喩 | jyy | 籠 | /hh | 肛 | ztt | 填 | onn |
| 嫉 | dtt | 侶 | stt | 冶 | att | 緻 | zgg | 諧 | ebb | 楷 | wbb |
| 嗅 | kyy | 瘍 | rgg | 羞 | ;yy | 辣 | .yy | 媛 | inn | 錮 | fvv |
| 罵 | ett | 梗 | uhh | 炒 | rtt | 摯 | xtt | 痩 | lmm | ||
| 璧 | iyy | 酎 | oyy | 惧 | uyy | 胚 | dbb | 哺 | svv | ||
| 曖 | ohh | 絆 | wtt | 貪 | pyy | 毀 | knn | 恣 | fbb | ||
上記の割り付け方は、漢字出現頻度と指の動きやすさ、熟語中の漢字のつながりなどから考えてみました。 また、新常用漢字から削除された「勺」、「錘」、「銑」、「脹」、「匁」については、もともとTUT-CODEに含まれている文字であるため、特に外してはいません。 また、新聞協会、共同通信、朝日新聞、NHKが独自に使用を決めた漢字の中で、TUT-CODEにも新常用漢字にもない「哨、疹、胚、炒、捧、鵜、肛、挽、絆、扮、杭」の11文字は、別途拡張コードの中に含めて追加割り付けしています。(なお 、このTUT-CODE定義ファイルはQWERTYキーボード用のみです)
新常用漢字対応 TUT-CODE定義ファイル ダウンロード GOOGLE-TUTp.zip
ファイルを解凍すると「roman.tut-code+.txt」が取り出せます。
オリジナルのTUT-CODE(2,525文字)定義ファイル ダウンロード GOOGLE-TUT.zip
ファイルを解凍すると「roman.tut-code.txt」が取り出せます。
なお、上記2ファイルともにオリジナルのTUT-CODEとは異なり、「づ」と「っ」のコードを入れ替えています。これは本来4ストロークの「っ」を3ストロークの「づ」と入れ替えることにより、「づ」に比べて良く使う「っ」の入力をスムーズに行うためです。また、GOOGLE 日本語入力ではオリジナルTUT−CODEの半角英記号+スペースキーの2ストロークで、一部の全角記号入力はサポートしていません。
GOOGLE 日本語入力で、TUT−CODE定義ファイルを設定する方法です。
新常用漢字対応 TUT-CODE定義ファイル ダウンロード WXG4TUTp.lzh
ファイルを解凍すると「WXG4TUT+.GRT」が取り出せます。
オリジナルのTUT-CODE(2,525文字)定義ファイル ダウンロード WXG4TUT.lzh
ファイルを解凍すると「WXG4TUT.GRT」が取り出せます。
なお、上記2ファイルともにオリジナルのTUT-CODEとは異なり、「づ」と「っ」のコードを入れ替えています。これは本来4ストロークの「っ」を3ストロークの「づ」と入れ替えることにより、「づ」に比べて良く使う「っ」の入力をスムーズに行うためです。
WXGで上記のTUT-CODE定義ファイルを利用する場合には、圧縮されたファイルを解凍して、現行のローマ字定義ファイルと同じDICフォルダ内に解凍後の「WXG4TUT.GRT」 または「WXG4TUT+.GRT」ファイルを入れてください。
さらに現行ローマ字定義ファイルからの変更には、WXGパレット(ここではバー型)の【環境設定】を選択します。

WXGのプロパティが出ますので、ここで【入力・変換】タブを選択し、カスタマイズボタンをクリックすると、WXGカスタマイザが起動されます。
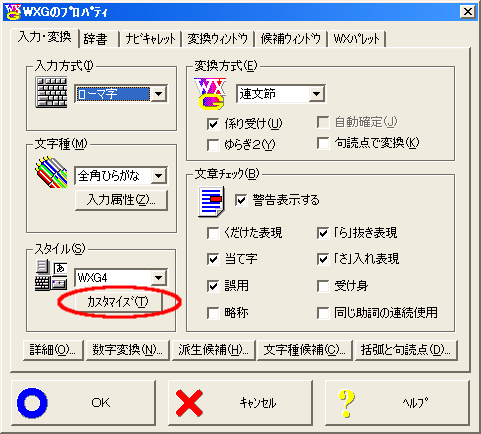
この状態で【ローマ字】ボタンをクリックします。
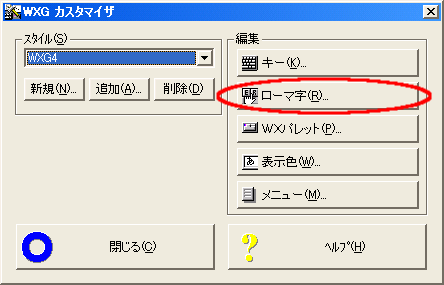
ドロップダウンリストで、「WXG4TUT:+.GRT」または、「WXG4TUT.GRT」を再選択するだけです。このとき必ずOKで終了してください。
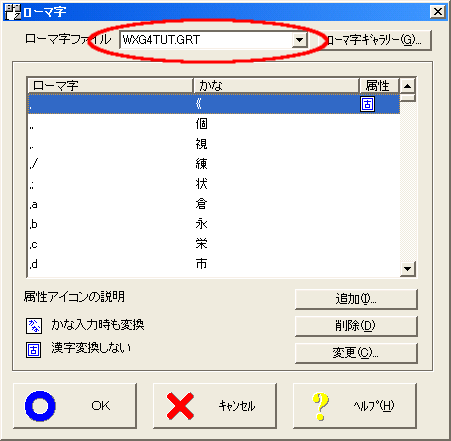
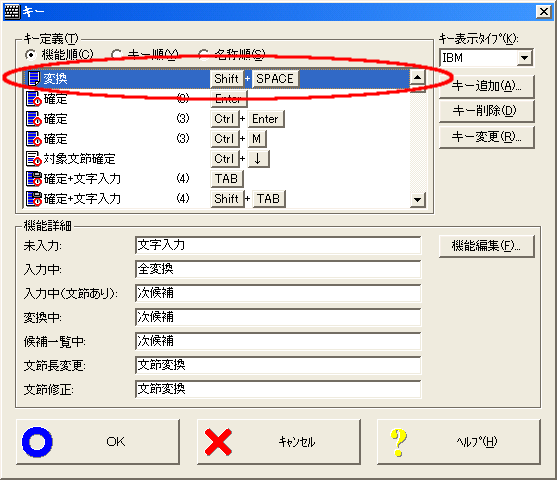
WXGの場合、TUT-CODEで定義された記号を2ストロークで入力しようとすると、スペースキーの機能割り付けを変更する必要があるようです。通常スペースキーは、かな漢字変換 機能に割り付けされておりますが、別のキー定義へ変更する方法は、WXGカスタマイザが起動された状態で、【キー】ボタンをクリックします。
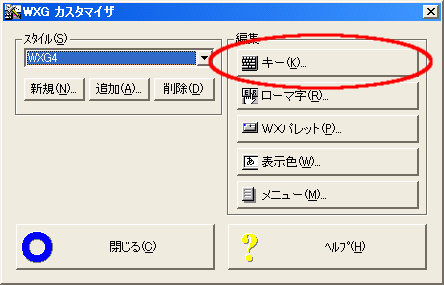
ここで「スペース」に割り付けられている「 変換」機能を例えば「Shift+SPACE」などに再設定できます。
NEW Ubuntu(14.04/18.04/20.04) Mozc用
Ubuntu20.04(日本語Remix版ではなく本家公式版)では、日本語入力にMozcを選択した場合に、通常のローマ字からTUT-CODEへ変更するためのプロパティが見当たりません。 このときはmozc-utils-guiをインストールすればプロパティが使用できるようになります。Ubuntu14.04/18.04と同じように解凍したTUT-CODE定義ファイルを読みこませるだけですが、 Ubuntu20.04のMozcはホームの場所に「mozc-table」フォルダはないようですので、適当な名前でフォルダを新規作成して、TUT-CODE定義ファイルをこの中に入れるとよいと思います。 ダウンロードした定義ファイルは圧縮されていますから、ファイルマネジャーから圧縮ファイルを選択した後で、マウスの右ボタンをクリックしてOpen(開く)―Extract(解凍)を選択し、 TUT-CODE定義ファイルを取り出します。
Ubuntu14.04/18.04(16.04からのアップグレード)の場合には、ファイルマネジャー(Nautilus)でホームの場所に「mozc-table」フォルダがあることを確認します。ダウンロードしたTUT-CODE定義ファイルはこのフォルダの中に入れてください。 定義ファイルは圧縮されていますから、ファイルマネジャーから圧縮ファイルを選択して、マウスの右ボタンをクリックして「ここに展開する」を選択します。
(注)この定義ファイルにはTUT-CODEのひらがな、漢字を定義しているだけです。半角ハイフン「-」文字から長音「ー」文字の変換などはMozcプロパティを利用して各自で自由に追加定義してください。(2021/12修正版 ファイルの改行をUNIX形式に統一、新常用漢字の一部不具合修正)
新常用漢字対応 TUT-CODE定義ファイル ダウンロード MOZCTUTp.zip
ファイルを展開すると「roman.tut-code+.txt」が取り出せます。
オリジナルのTUT-CODE(2,525文字)定義ファイル ダウンロード MOZCTUT.zip
ファイルを展開すると「roman.tut-code.txt」が取り出せます。
なお、上記2ファイルともにオリジナルのTUT-CODEとは異なり、「づ」と「っ」のコードを入れ替えています。これは本来4ストロークの「っ」を3ストロークの「づ」と入れ替えることにより、「づ」に比べて良く使う「っ」の入力をスムーズに行うためです。 また、WXG用では半角英記号+スペースキーの2ストロークで一部の全角記号入力をサポートしていましたが、Mozc用ではサポートしていません。
ここではUbuntu24.04について説明します。MozcIME入力ができる状態で、Mozc設定ツールを起動します。Mozcプロパティが表示されたら、「ローマ字テーブル」の編集をクリックします。
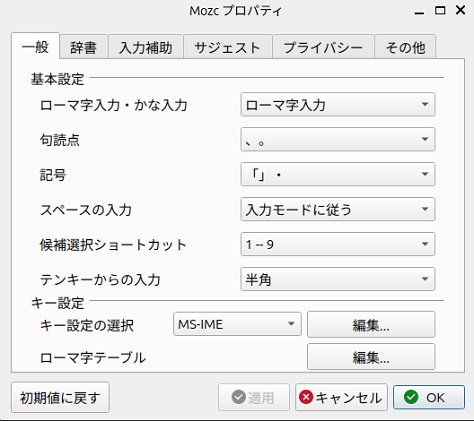
Mozcローマ字テーブル設定画面になるので、「編集─インポート」を選択して、Mozc用のTUT-CODE定義ファイルを読み込みますが、「現在のローマ字テーブルを上書きしますか?」と確認メッセージが出たら「はい」を選択します。
TUT-CODEの変換テーブルに変わったことを確認して「OK」をクリックすると、元のMozcプロパティ画面に戻ります。
最後にMozcプロパティ画面で「適用」、「OK」をクリックして終了します。
